Руководство. Сбор данных Центров событий в формате Parquet и их анализ с помощью Azure Synapse Analytics
В этом руководстве показано, как с помощью редактора кода Stream Analytics создать задание, которое записывает данные Центров событий в Azure Data Lake Storage 2-го поколения в формате Parquet.
В этом руководстве описано следующее:
- Развертывание генератора событий, который отправляет примеры событий в концентратор событий
- Создание задания Stream Analytics с помощью портала Microsoft Azure
- Проверка входных данных и схемы
- Настройка Azure Data Lake Storage 2-го поколения, в которую будут записываться данные концентратора событий
- Выполнение задания Stream Analytics
- Использование Azure Synapse Analytics для запроса файлов Parquet
Предварительные требования
Прежде чем начать работу, нужно сделать следующее:
- Если у вас еще нет подписки Azure, создайте бесплатную учетную запись Azure.
- Разверните приложение генератора событий TollApp в Azure. Задайте для параметра interval значение 1 и используйте для этого шага новую группу ресурсов.
- Создайте рабочую область Azure Synapse Analytics с учетной записью Data Lake Storage 2-го поколения.
Не используйте редактор кода для создания задания Stream Analytics
Найдите группу ресурсов, в которой развернут генератор событий TollApp.
Выберите пространство имен Центров событий.
На странице Пространство имен Центров событий выберите Центры событий в разделе Объекты в меню слева.
Выберите
entrystreamэкземпляр.
На странице Экземпляр Центров событий выберите Обрабатывать данные в разделе Функции в меню слева.
Выберите Начать на плитке Запись данных в ADLS 2-го поколения в формате Parquet.

Присвойте задание
parquetcaptureимя и нажмите кнопку Создать.
На странице конфигурации концентратора событий подтвердите следующие параметры и выберите Подключить.
Группа потребителей: по умолчанию
Тип сериализации входных данных: JSON
Режим проверки подлинности, который задание будет использовать для подключения к концентратору событий: строка подключения.

Через несколько секунд вы увидите пример входных данных и схему. Вы можете удалить поля, переименовать их или изменить тип данных.
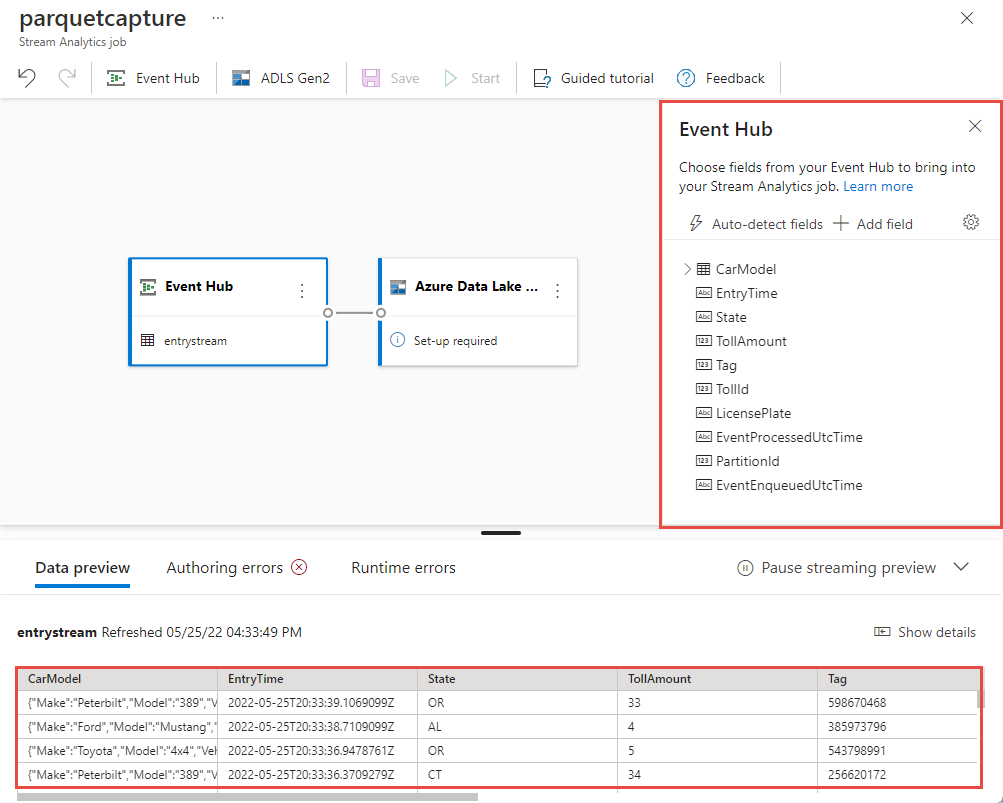
Выберите элемент Azure Data Lake Storage 2-го поколения на панели холста и настройте его, указав
- Подписку, в которой находится учетная запись Azure Data Lake 2-го поколения
- Имя учетной записи хранения, которое должна совпадать с учетной записью ADLS 2-го поколения, используемой с рабочей областью Azure Synapse Analytics, выполненной в разделе "Предварительные требования".
- Контейнер, в котором будут созданы файлы Parquet.
- Шаблон пути: {date}/{time}
- Шаблон даты и времени в качестве даты и времени по умолчанию гггг-мм-дд и ЧЧ.
- Щелкните Подключиться.

Нажмите кнопку Сохранить на верхней ленте, чтобы сохранить задание, а затем нажмите кнопку Запустить , чтобы запустить задание. После запуска задания выберите X в правом углу, чтобы закрыть страницу задания Stream Analytics .

Затем вы увидите список всех заданий Stream Analytics, созданных с помощью редактора кода. И в течение двух минут задание перейдет в состояние Выполняется. Нажмите кнопку Обновить на странице, чтобы увидеть, что состояние изменено с Создано —>Запуск> — Выполняется.









Просмотр выходных данных в учетной записи Azure Data Lake Storage 2-го поколения
Найдите учетную запись Azure Data Lake Storage 2-го поколения, использованную на предыдущем шаге.
Выберите контейнер, использованный на предыдущем шаге. Вы увидите файлы Parquet, созданные на основе шаблона пути {date}/{time}, используемого на предыдущем шаге.
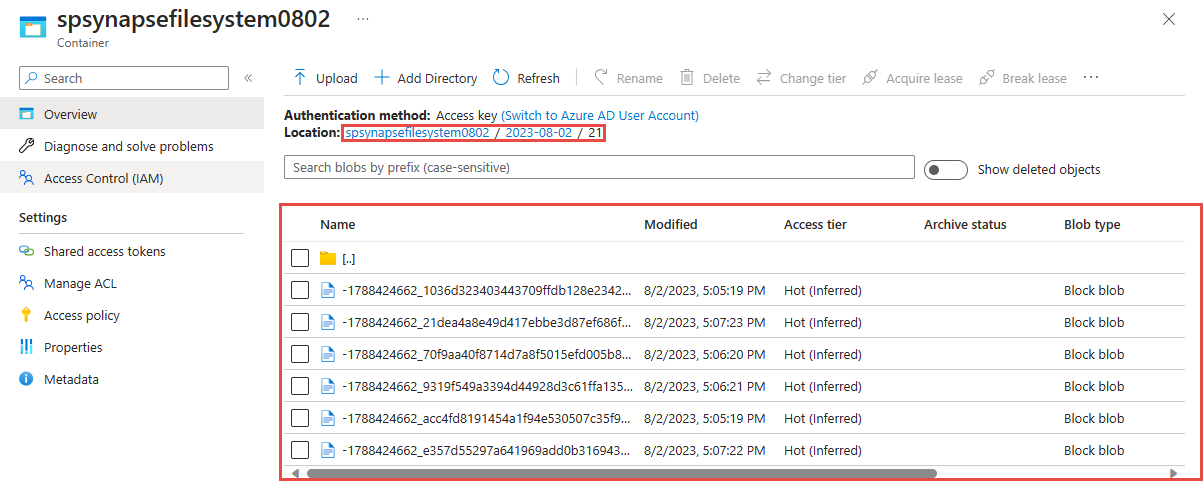
Запрос собранных данных в формате Parquet с помощью Azure Synapse Analytics
Запрос с использованием Azure Synapse Spark
Найдите рабочую область Azure Synapse Analytics и откройте Synapse Studio.
Создайте бессерверный пул Apache Spark в рабочей области, если таковой еще не существует.
В Synapse Studio перейдите в центр Разработка и создайте новую Записную книжку.
Создайте новую ячейку кода и вставьте в нее следующий код. Замените контейнер и adlsname именем контейнера и учетной записи ADLS 2-го поколения, используемой на предыдущем шаге.
%%pyspark df = spark.read.load('abfss://container@adlsname.dfs.core.windows.net/*/*/*.parquet', format='parquet') display(df.limit(10)) df.count() df.printSchema()Для параметра Присоединиться к на панели инструментов выберите пул Spark из раскрывающегося списка.
Снова нажмите кнопку Выполнить все, чтобы просмотреть результаты.


Запрос с использованием бессерверных SQL Azure Synapse
В центре Разработка создайте новый скрипт SQL.
Вставьте следующий скрипт и запустите его с помощью встроенной бессерверной конечной точки SQL. Замените контейнер и adlsname именем контейнера и учетной записи ADLS 2-го поколения, используемой на предыдущем шаге.
SELECT TOP 100 * FROM OPENROWSET( BULK 'https://adlsname.dfs.core.windows.net/container/*/*/*.parquet', FORMAT='PARQUET' ) AS [result]

Очистка ресурсов
- Найдите экземпляр Центров событий и просмотрите список заданий Stream Analytics в разделе Обработка данных. Остановите все работающие задания.
- Перейдите в группу ресурсов, которую вы использовали при развертывании генератора событий TollApp.
- Выберите Удалить группу ресурсов. Введите имя группы ресурсов, чтобы подтвердить удаление.
Дальнейшие действия
В этом руководстве вы узнали, как создать задание Stream Analytics с помощью редактора кода для записи потоков данных Центров событий в формате Parquet. Затем вы использовали Azure Synapse Analytics для запроса файлов Parquet с помощью Synapse Spark и Synapse SQL.