
Data Lake
Um Data Lake sem limites para impulsionar a ação inteligente.
- Armazenar e analisar arquivos de petabytes de tamanho e trilhões de objetos
- Depurar e otimizar seus programas de Big Data com facilidade
- Iniciar em segundos, dimensionar instantaneamente, pagar por trabalho
- Desenvolver programas paralelos de forma massiva, com simplicidade
- Segurança de nível empresarial, auditoria e suporte
- Integrado ao YARN, projetado para a nuvem
O Azure Data Lake inclui todos os recursos necessários para que seja mais fácil para desenvolvedores, cientistas de dados e analistas armazenar dados de qualquer tamanho, forma e velocidade, bem como realizar todo tipo de processamento e análise em diferentes plataformas e linguagens. Ele remove as complexidades relacionadas a ingerir e armazenar todos os seus dados, enquanto acelera a execução de análises em lote, streaming e interativas. O Azure Data Lake trabalha com investimentos existentes em TI para oferecer identidade, gerenciamento e segurança para que haja um controle e um gerenciamento de dados simplificados. Ele também tem integração direta com repositórios operacionais e data warehouses, de modo que você pode ampliar aplicativos de dados atuais. Aproveitamos nossa experiência de trabalho com clientes empresariais e da execução de algumas das análises e processamentos de maior escala no mundo para produtos da Microsoft como Office 365, Xbox Live, Azure, Windows, Bing e Skype. O Azure Data Lake soluciona muitos dos desafios de produtividade e escalabilidade que o impedem de maximizar o valor de seus ativos de dados com um serviço que está pronto para atender as suas necessidades comerciais atuais e futuras.
O Azure Data Lake inclui todos os recursos necessários para que seja mais fácil para desenvolvedores, cientistas de dados e analistas armazenar dados de qualquer tamanho, forma e velocidade, bem como realizar todo tipo de processamento e análise em diferentes plataformas e linguagens. Ele remove as complexidades relacionadas a ingerir e armazenar todos os seus dados, enquanto acelera a execução de análises em lote, streaming e interativas. O Azure Data Lake trabalha com investimentos existentes em TI para oferecer identidade, gerenciamento e segurança para que haja um controle e um gerenciamento de dados simplificados. Ele também tem integração direta com repositórios operacionais e data warehouses, de modo que você pode ampliar aplicativos de dados atuais. Aproveitamos nossa experiência de trabalho com clientes empresariais e da execução de algumas das análises e processamentos de maior escala no mundo para produtos da Microsoft como Office 365, Xbox Live, Azure, Windows, Bing e Skype. O Azure Data Lake soluciona muitos dos desafios de produtividade e escalabilidade que o impedem de maximizar o valor de seus ativos de dados com um serviço que está pronto para atender as suas necessidades comerciais atuais e futuras.
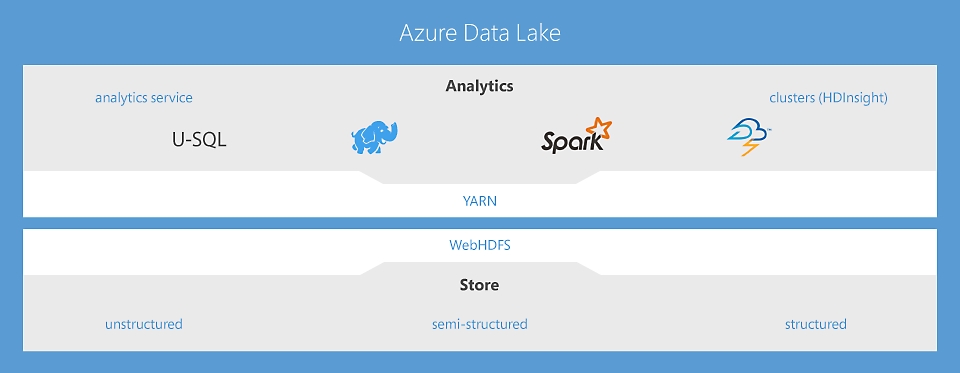
Data Lake Analytics – um serviço de trabalho de análise ilimitado para impulsionar a ação inteligente
O primeiro serviço de análise na nuvem no qual é possível desenvolver e executar transformação paralela de dados de forma massiva e processamento de programas em U-SQL, R, Python e .NET em petabytes de dados. Sem infraestrutura para gerenciar, processe dados sob demanda, dimensione instantaneamente e pague somente por trabalho. Saiba mais

HDInsight – serviço de nuvem Apache Spark e Hadoop® para a empresa
O HDInsight é a única oferta completamente gerenciada de Hadoop de nuvem, que oferece clusters de análise de software livre otimizados para Spark, Hive, Map Reduce, HBase, Storm, Kafka e R-Server com suporte de SLA de 99,9%. Cada uma dessas tecnologias de Big Data, assim como aplicativos de ISV (fornecedor independente de software), são facilmente implantáveis e gerenciados como clusters, com segurança e monitoramento de nível empresarial. Saiba mais

Data Lake Store – um data lake ilimitado que impulsiona a análise de Big Data
O primeiro Data Lake de nuvem para empresas que é seguro, massivamente escalonável e criado para o padrão aberto do HDFS. Sem limites para o tamanho dos dados e com a habilidade para executar análises massivamente paralelas, agora você pode desbloquear o valor de todos os seus dados não estruturados, semiestruturados e estruturados. Saiba mais

Desenvolver, depurar e otimizar seus programas de Big Data com facilidade
Pode ser difícil encontrar as ferramentas certas para elaborar e ajustar suas consultas de Big Data. O Data Lake facilita esse processo através da ampla integração com o Visual Studio, o Eclipse e o IntelliJ, para que você possa usar ferramentas com as quais já está familiarizado para executar, depurar e ajustar códigos. As visualizações de trabalhos do U-SQL, do Apache Spark, do Apache Hive e do Apache Storm permitem ver como o código é executado em escala, bem como identificar gargalos de desempenho e otimizações de custos, o que facilita o ajuste das consultas. Nosso ambiente de execução analisa ativamente seus programas enquanto eles são executados e oferece recomendações para melhorar o desempenho e reduzir custos. Engenheiros de dados, DBAs e arquitetos de dados podem usar habilidades existentes, como SQL, Apache Hadoop, Apache Spark, R, Python, Java e .NET para serem produtivos desde o primeiro dia.

Integração total com seus investimentos de TI existentes
Um dos principais desafios do Big Data é a integração com os investimentos de TI existentes. O Data Lake é uma parte fundamental da Cortana Intelligence, o que significa que ele funciona com o Azure Synapse Analytics, o Power BI e o Data Factory formando uma plataforma completa de análise avançada e Big Data na nuvem que ajuda você em todos os estágios, desde a preparação de dados à realização de análises interativas em conjuntos de dados de grande escala. O Data Lake Analytics dá a você o poder para agir em todos os seus dados com virtualização otimizada de dados de suas fontes relacionais como o SQL Server do Azure em máquinas virtuais, o Banco de Dados SQL do Azure e o Azure Synapse Analytics. As consultas são otimizadas automaticamente, movendo o processamento para perto dos dados de origem, sem a movimentação de dados, maximizando assim o desempenho e minimizando a latência. Além disso, como o Data Lake está inserido no Azure, você pode conectar-se a qualquer dado gerado pelos aplicativos ou consumido pelos dispositivos nos cenários de IoT (Internet das Coisas).
Armazenar e analisar arquivos de petabytes de tamanho e trilhões de objetos
O Data Lake foi projetado desde o início para proporcionar escala e desempenho na nuvem. Com o Azure Data Lake Store, sua organização pode analisar todos os seus dados em um único lugar, sem restrições artificiais. Seu Data Lake Store pode armazenar trilhões de arquivos, sendo que um único arquivo pode ter tamanho maior que um petabyte, o que é 200 vezes maior que outros repositórios de nuvem. Isso quer dizer que você não precisa reescrever os códigos conforme o aumento ou a diminuição do tamanho dos dados armazenados ou da quantidade de computação usada. Isso permite que você se concentre na lógica dos seus negócios e não no processamento e armazenamento de grandes conjuntos de dados. O Data Lake também elimina a complexidade que geralmente está associada ao Big Data na nuvem, o que garante que ele atenderá às suas necessidades comerciais atuais e futuras.

Financeiramente viável e econômico
O Data Lake é uma solução econômica para executar cargas de trabalho de Big Data. Você pode optar por clusters sob demanda ou um modelo de pagamento por trabalho quando os dados forem processados. Nos dois casos, não é necessário adquirir hardware nem contratar licenças ou contratos de suporte específicos para serviços. É possível ampliar ou reduzir a escala do sistema de acordo com suas necessidades comerciais, o que quer dizer que você nunca paga mais que o necessário. Ele também permite dimensionar de maneira independente o armazenamento e a computação, o que proporciona mais flexibilidade econômica em comparação com as soluções de Big Data tradicionais. Além disso, ele minimiza a necessidade de contratar equipes operacionais especializadas, que normalmente associadas a execução de infraestruturas de Big Data. O Data Lake minimiza seus custos e maximiza o retorno sobre seu investimento em dados. Um estudo recente mostrou o HDInsight entregando um TCO (custo total de propriedade) 63% menor em comparação com a implantação do Hadoop local durante cinco anos.

Segurança de nível empresarial, auditoria e suporte
O Data Lake tem suporte e é completamente gerenciado pela Microsoft, que também fornece SLA e suporte de nível empresarial. Você pode entrar em contato conosco por meio do atendimento ao cliente – disponível 24 horas por dia, 7 dias por semana – para solucionar qualquer problema que surja na solução de Big Data. Nossa equipe monitora a sua implantação para você, garantindo assim a sua execução contínua. O Data Lake protege seus ativos de dados e estende sua segurança e controle de governança local para a nuvem com facilidade. Os dados são Always Encrypted; dinamicamente pelo uso de SSL e em repouso pelo uso de chaves protegidas por HSM gerenciadas por serviço ou pelo usuário no Azure Key Vault. O SSO (logon único), a autenticação multifator e o gerenciamento contínuo de milhões de identidades são recursos internos do Azure Active Directory. Você pode autorizar usuários e grupos com ACLs (listas de controle de acesso) baseadas em POSIX com permissões refinadas sobre todos os dados no repositório, habilitando controles de acesso baseados em função. Por fim, você pode atender necessidades de segurança e conformidade a normas, auditando cada acesso ou mudança de configuração no sistema.
Compile soluções do Data Lake usando essas soluções avançadas

HDInsight
Provisione clusters Hadoop, Spark, Servidor R, HBase e Storm na nuvem.

Data Lake Analytics
Serviço de análises distribuído que facilita o uso de Big Data.
Azure Data Lake Storage
Data Lake escalável e seguro para análises de alto desempenho.