Monitorar Site Recovery com os logs do Azure Monitor
Este artigo descreve como monitorar as máquinas replicadas pelo Azure Site Recovery, usando osLogs do Azure Monitor e aAnálise de Logs.
Os Logs do Azure Monitor fornece uma plataforma de dados de reistro que coleta os logs da atividade e de recursos, juntamente com outros dados de monitoramento. Nos Logs do Azure Monitor, use o Log Analytics para escrever e testar consultas de log e analisar os dados de log de maneira interativa. Visualize e consulte os resultados do log e configure os alertas para executar ações com base nos dados monitorados.
Para a Recuperação de site, você pode usar os Logs do Azure Monitor para ajudá-lo a fazer o seguinte:
- Monitorar a integridade e o status da Recuperação de site. Por exemplo, você pode monitorar a integridade da replicação, o estado do failover de teste, eventos do Site Recovery, RPOs (objetivos de ponto de recuperação) para computadores protegidos e taxas de alteração de disco/dados.
- Configure alertas para o Azure Site Recovery. Por exemplo, você pode configurar alertas para a integridade do computador, o status do failover de teste ou status de trabalho do Azure Site Recovery.
Há suporte para o uso dos Logs do Azure Monitor com o Site Recovery na replicação do Azure para o Azure e na replicação do servidor físico/da VM do VMware para o Azure.
Observação
Para obter os logs dos dados de rotatividade e os logs da taxa de upload para VMware e as máquinas físicas, você precisa instalar um Agente de Monitoramento do Microsoft Intune no servidor de processo. Este agente envia os logs da replicação das máquinas para o espaço de trabalho. Essa funcionalidade só está disponível para a versão do agente de mobilidade 9.30 em diante.
Pré-requisitos
Você precisa do seguinte:
- Pelo menos um computador está protegido em um cofre dos Serviços de Recuperação.
- Um espaço de trabalho do Log Analytics para armazenar os logs do Azure Site Recovery. Saiba mais sobre comoConfigurar um espaço de trabalho.
- Um reconhecimento básico de como gravar, executar e analisar consultas de log no Log Analytics. Saiba mais.
Recomendamos que você revise asperguntas comuns de monitoramentoantes de iniciar.
Configurar o Azure Site Recovery para enviar os logs
No cofre, selecione Configurações de diagnóstico>Adicionar configuração de diagnóstico.
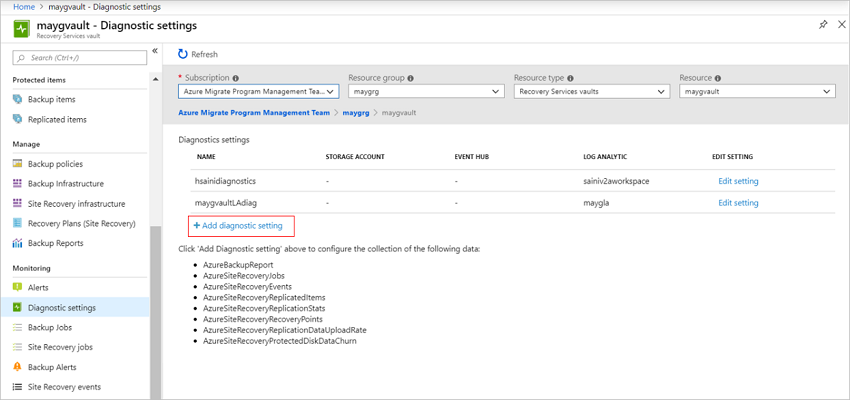
EmConfigurações de diagnóstico,especifique um nome e verifique a caixa de seleçãoEnviar para o Log Analytics.
Selecione a assinatura dos Logs do Azure Monitor e o workspace do Log Analytics.
SelecioneDiagnóstico do Azureno botão de alternância.
Na lista log, selecione tudo dos logs com o prefixoAzureSiteRecovery. Depois, selecione OK.
Os logs do Azure Site Recovery iniciam o feed em uma tabela (AzureDiagnostics) no espaço de trabalho selecionado.
Configurar o Agente de Monitoramento da Microsoft no Servidor de Processo para enviar a rotatividade e carregar os logs de taxa
Você pode capturar as informações dos dados de rotatividade e das informações da taxa dos dados de origem de upload para seus computadores VMware/físicos no local. Para habilitar isto, é necessário que um Agente de Monitoramento da Microsoft esteja instalado no servidor de processo.
Acesse o workspace do Log Analytics e selecione Configurações Avançadas.
Selecione a página Fontes Conectadas e selecione Servidores do Windows.
Baixe o Agente do Windows (64 bits) no Servidor de Processo.
Conclua a instalação do agentefornecendo a ID e a chave obtidas no espaço de trabalho.
Assim que a instalação for concluída, acesse o workspace do Log Analytics e selecione Gerenciamento de agentes herdados. Vá para a página Dados e selecione Contadores de Desempenho do Windows.
Selecione '+' para adicionar os dois seguintes contadores com um intervalo de amostragem de 300 segundos:
- ASRAnalytics(*)\SourceVmChurnRate
- ASRAnalytics(*)\SourceVmThrpRate
Os dados da taxa de rotatividade e de upload começarão a alimentar no espaço de trabalho.
Consultar os logs- amostras
Você recupera os dados de logs usando as consultas de log escritas com aLinguagem de Consulta Kusto. Esta seção fornece alguns exemplos de consultas comuns que você pode usar para o monitoramento do Azure Site Recovery.
Observação
Alguns dos exemplos usam oreplicationProviderName_sdefinido comoA2A. Isto recupera as VMs do Azure que são replicadas para uma Região Secundária do Azure usando o Azure Site Recovery. Nestes exemplos, você pode substituirA2AporInMageRcm,se desejar recuperar VMs VMware locais ou servidores físicos que são replicados para o Azure usando o azure Site Recovery.
Consulta da integriadade da replicação
Essa consulta exibe um gráfico de pizza da integridade da replicação atual de todas as VMs do Azure protegidas, divididas em três Estados: Normal, Aviso ou Crítico.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project name_s , replicationHealth_s
| summarize count() by replicationHealth_s
| render piechart
Versão da consulta do serviço Mobilidade
Esta consulta exibe um gráfico de pizza das VMs do Azure replicadas com o Site Recovery, divididas pela versão do agente de mobilidade que estão em execução.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project name_s , agentVersion_s
| summarize count() by agentVersion_s
| render piechart
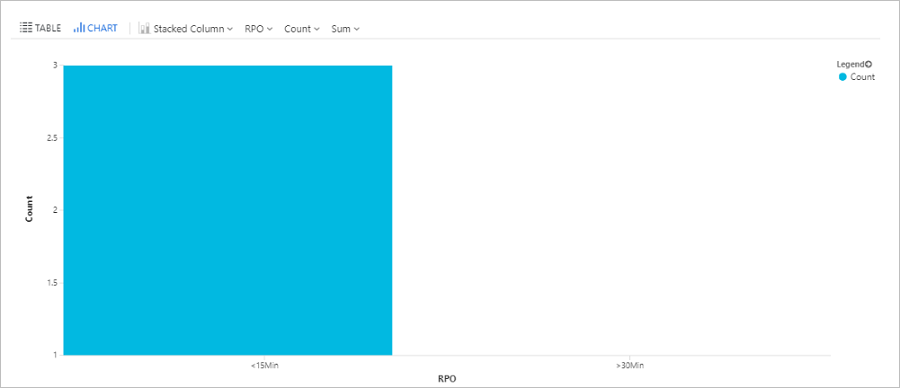
Tempo da consulta do RPO
Esta consulta exibe um gráfico de barras das VMs do Azure replicadas com o Site Recovery, divididas pelo RPO (objetivo de ponto de recuperação): Less de 15 minutos, entre 15-30 minutos, mais de 30 minutos.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| extend RPO = case(rpoInSeconds_d <= 900, "<15Min",
rpoInSeconds_d <= 1800, "15-30Min", ">30Min")
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project name_s , RPO
| summarize Count = count() by RPO
| render barchart
Consulta de trabalhos do Azure Site Recovery
Esta consulta recupera todos os trabalhos do Azure Site Recovery (de todos os cenários de recuperação de desastre), disparados nas últimas 72 horas e seu estado de conclusão.
AzureDiagnostics
| where Category == "AzureSiteRecoveryJobs"
| where TimeGenerated >= ago(72h)
| project JobName = OperationName , VaultName = Resource , TargetName = affectedResourceName_s, State = ResultType
Consultas dos Eventos do Azure Site Recovery
Esta consulta recupera todos os eventos de Site Recovery (de todos os cenários de recuperação de desastre) gerados nas últimas 72 horas, juntamente com sua gravidade.
AzureDiagnostics
| where Category == "AzureSiteRecoveryEvents"
| where TimeGenerated >= ago(72h)
| project AffectedObject=affectedResourceName_s , VaultName = Resource, Description_s = healthErrors_s , Severity = Level
Consulta do teste de estado do failover (gráfico de pizza)
Esta consulta exibe um gráfico de pizza do teste de estado do failover das VMs do Azure replicadas com o Azure Site Recovery.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| where isnotempty(failoverHealth_s) and isnotnull(failoverHealth_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project name_s , Resource, failoverHealth_s
| summarize count() by failoverHealth_s
| render piechart
Consulta do teste de estado do failover (tabela)
Esta consulta exibe uma tabela do teste de estado do failover das VMs do Azure replicadas com o Azure Site Recovery.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| where isnotempty(failoverHealth_s) and isnotnull(failoverHealth_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project VirtualMachine = name_s , VaultName = Resource , TestFailoverStatus = failoverHealth_s
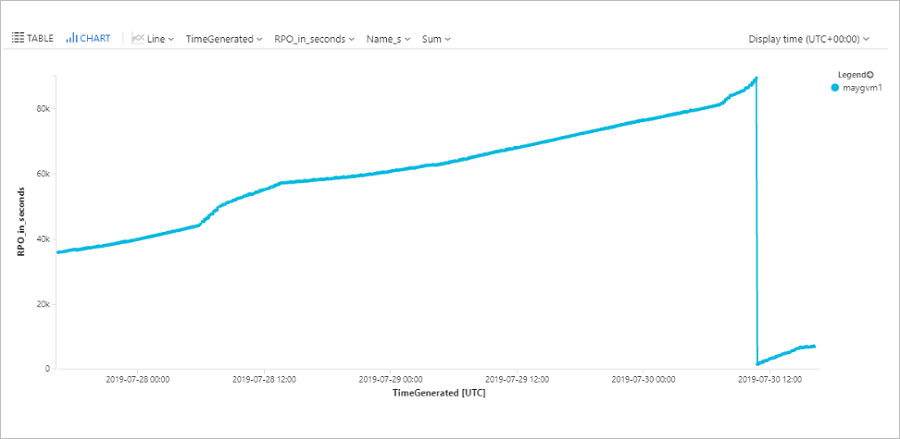
Consulta do computador RPO
Esta consulta exibe um gráfico de tendências que acompanha o RPO de uma VM específica do Azure (ContosoVM123) nas últimas 72 horas.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where TimeGenerated > ago(72h)
| where isnotempty(name_s) and isnotnull(name_s)
| where name_s == "ContosoVM123"
| project TimeGenerated, name_s , RPO_in_seconds = rpoInSeconds_d
| render timechart
Consulta da taxa de alteração de dados (rotatividade) e da taxa de upload de uma VM do Azure
Esta consulta exibe um gráfico de tendências de uma VM do Azure específica (ContosoVM123), que representa a taxa de alteração de dados (bytes de gravação por segundo) e a taxa de carregamento de dados.
AzureDiagnostics
| where Category in ("AzureSiteRecoveryProtectedDiskDataChurn", "AzureSiteRecoveryReplicationDataUploadRate")
| extend CategoryS = case(Category contains "Churn", "DataChurn",
Category contains "Upload", "UploadRate", "none")
| extend InstanceWithType=strcat(CategoryS, "_", InstanceName_s)
| where TimeGenerated > ago(24h)
| where InstanceName_s startswith "ContosoVM123"
| project TimeGenerated , InstanceWithType , Churn_MBps = todouble(Value_s)/1048576
| render timechart
Consulta da taxa de alteração de dados (rotatividade) e da taxa de upload de um VMware ou computador físico
Observação
Verifique se você configurou o agente de monitoramento no Servidor de Processo para efetuar fetch desses logs. Consulte as etapas para configurar o agente de monitoramento.
Esta consulta exibe um grafo de tendências para um disco específico, disk0, de um item replicado, win-9r7sfh9qlru, que representa a taxa de alteração de dados (bytes de gravação por segundo) e a taxa de carregamento de dados. Encontre o nome do disco na folha Discos do item replicado no cofre dos Serviços de Recuperação. O nome da instância a ser usado na consulta é o nome DNS do computador seguido de _ e o nome do disco, como neste exemplo.
Perf
| where ObjectName == "ASRAnalytics"
| where InstanceName contains "win-9r7sfh9qlru_disk0"
| where TimeGenerated >= ago(4h)
| project TimeGenerated ,CounterName, Churn_MBps = todouble(CounterValue)/5242880
| render timechart
O Servidor de Processo efetua push destes dados a cada 5 minutos para o espaço de trabalho do Log Analytics. Estes pontos de dados representam a média computada por 5 minutos.
Resumo da consulta da recuperação de desastre (Azure para Azure)
Esta consulta exibe uma tabela do resumo das VMs do Azure replicadas de uma Região Secundária do Azure. Ela mostra o nome da VM, o status da replicação e da proteção, o RPO, o status do failover de teste, a versão do agente de Mobilidade, os erros de replicação ativos e o local de origem.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project VirtualMachine = name_s , Vault = Resource , ReplicationHealth = replicationHealth_s, Status = protectionState_s, RPO_in_seconds = rpoInSeconds_d, TestFailoverStatus = failoverHealth_s, AgentVersion = agentVersion_s, ReplicationError = replicationHealthErrors_s, SourceLocation = primaryFabricName_s
Resumo da consulta da recuperação de desastre (servidores VMware/físicos)
Esta consulta exibe uma tabela de resumo das VMs VMware e dos servidores físicos replicados para o Azure. Ela mostra o nome do computador, o status da replicação e da proteção, o RPO, o status do failover de teste, a versão do agente de Mobilidade, os erros de replicação ativos e o servidor de processo relevante.
AzureDiagnostics
| where replicationProviderName_s == "InMageRcm"
| where isnotempty(name_s) and isnotnull(name_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project VirtualMachine = name_s , Vault = Resource , ReplicationHealth = replicationHealth_s, Status = protectionState_s, RPO_in_seconds = rpoInSeconds_d, TestFailoverStatus = failoverHealth_s, AgentVersion = agentVersion_s, ReplicationError = replicationHealthErrors_s, ProcessServer = processServerName_g
Configurar alertas-amostras
Você pode configurar os alertas de Site Recovery com base nos dados do Azure Monitor. Saiba maissobre como configurar os alertas do log.
Observação
Alguns dos exemplos usam oreplicationProviderName_sdefinido comoA2A. Isto define alertas das VMs do Azure que são replicadas de uma Região Secundária do Azure. Nestes exemplos, você pode substituirA2AporInMageRcm,se desejar definir os alertas das VMs VMware locais ou servidores físicos replicados para o Azure.
Diversos computadores em um estado crítico
Configure um alerta se mais de 20 VMs replicadas do Azure entrarem em um estado crítico.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where replicationHealth_s == "Critical"
| where isnotempty(name_s) and isnotnull(name_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| summarize count()
Para o alerta, defina o Valor limite como 20.
Computador simples em estado crítico
Configure um alerta se uma VM replicada específica do Azure entrar em um estado crítico.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where replicationHealth_s == "Critical"
| where name_s == "ContosoVM123"
| where isnotempty(name_s) and isnotnull(name_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| summarize count()
Para o alerta, defina o Valor limite como 1.
Diversos computadores excedem o RPO
Configure um alerta se o RPO de mais de 20 VMs do Azure exceder 30 minutos.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| where rpoInSeconds_d > 1800
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project name_s , rpoInSeconds_d
| summarize count()
Para o alerta, defina o Valor limite como 20.
O computador simples excede o RPO
Configure um alerta se o RPO de uma VM simples do Azure exceder 30 minutos.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| where name_s == "ContosoVM123"
| where rpoInSeconds_d > 1800
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project name_s , rpoInSeconds_d
| summarize count()
Para o alerta, defina o Valor limite como 1.
O failover de teste de vários computadores excede 90 dias
Configure um alerta se o último failover de teste de êxito tiver mais de 90 dias, para mais de 20 VMs.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where Category == "AzureSiteRecoveryReplicatedItems"
| where isnotempty(name_s) and isnotnull(name_s)
| where lastSuccessfulTestFailoverTime_t <= ago(90d)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| summarize count()
Para o alerta, defina o Valor limite como 20.
O failover de teste de um só computador excede 90 dias
Configure um alerta se o último failover de teste bem-sucedido tiver mais de 90 dias.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where Category == "AzureSiteRecoveryReplicatedItems"
| where isnotempty(name_s) and isnotnull(name_s)
| where lastSuccessfulTestFailoverTime_t <= ago(90d)
| where name_s == "ContosoVM123"
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| summarize count()
Para o alerta, defina o Valor limite como 1.
Falha no trabalho do Site Recovery
Configure um alerta se um trabalho de Site Recovery (neste caso, o trabalho de proteção novamente) falhar para qualquer cenário de Site Recovery, durante o último dia.
AzureDiagnostics
| where Category == "AzureSiteRecoveryJobs"
| where OperationName == "Reprotect"
| where ResultType == "Failed"
| summarize count()
Para o alerta, defina oValor Limitecomo 1 ePeríodo de Retençãocomo 1440 minutos para verificar falhas no último dia.
Próximas etapas
Saiba mais sobreo monitoramento interno do site Recovery.