Przekształcanie danych przez uruchomienie działania języka Python w usłudze Azure Databricks
DOTYCZY: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Porada
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric, czyli rozwiązanie do analizy all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
Działanie języka Python usługi Azure Databricks w potoku uruchamia plik języka Python w klastrze usługi Azure Databricks. Ten artykuł opiera się na artykule dotyczącym działań przekształcania danych , który przedstawia ogólne omówienie transformacji danych i obsługiwanych działań przekształcania. Azure Databricks to zarządzana platforma do uruchamiania platformy Apache Spark.
Poniższy klip wideo zawiera jedenastominutowe wprowadzenie i demonstrację tej funkcji:
Dodawanie działania języka Python dla usługi Azure Databricks do potoku za pomocą interfejsu użytkownika
Aby użyć działania języka Python dla usługi Azure Databricks w potoku, wykonaj następujące kroki:
Wyszukaj język Python w okienku Działania potoku i przeciągnij działanie języka Python na kanwę potoku.
Wybierz nowe działanie języka Python na kanwie, jeśli nie zostało jeszcze wybrane.
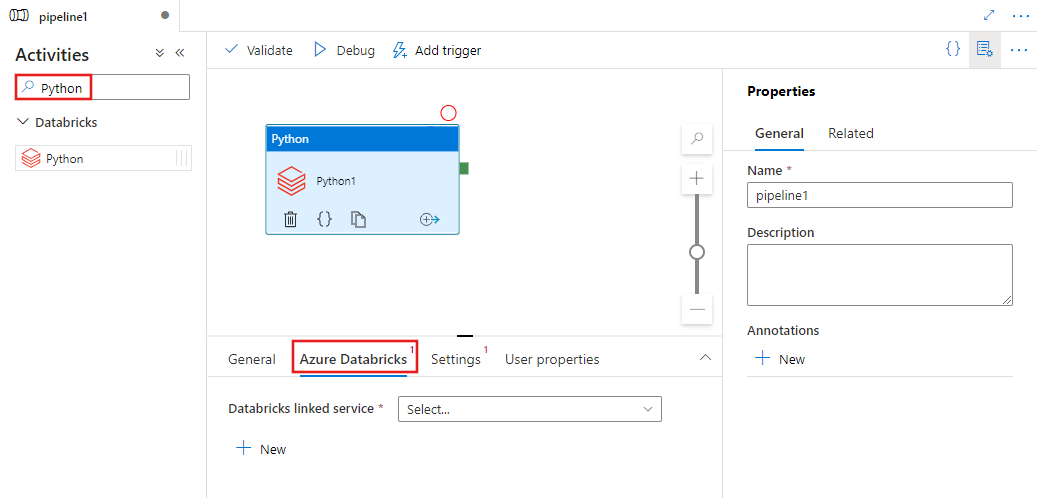
Wybierz kartę Azure Databricks , aby wybrać lub utworzyć nową połączoną usługę Azure Databricks, która wykona działanie języka Python.
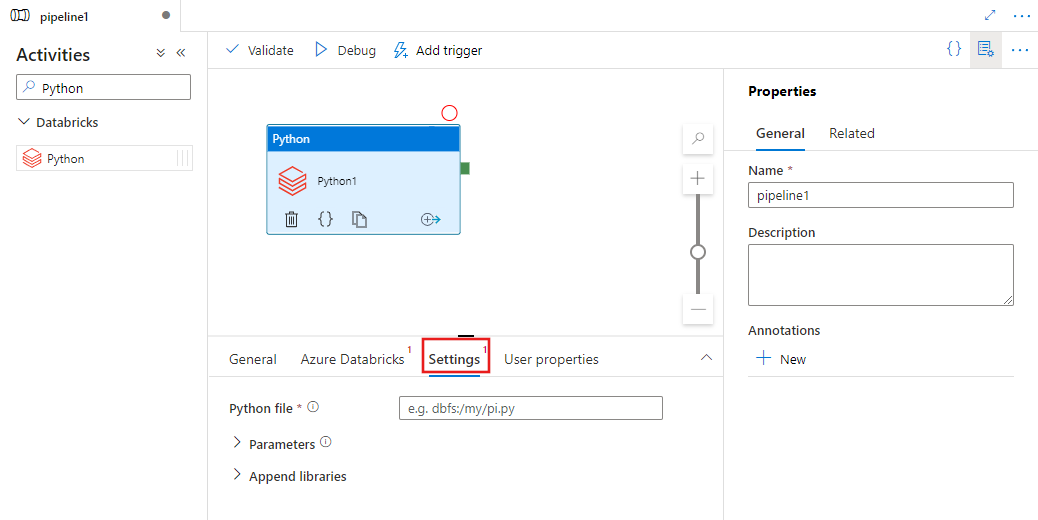
Wybierz kartę Ustawienia i określ ścieżkę w usłudze Azure Databricks do pliku języka Python do wykonania, parametry opcjonalne do przekazania oraz wszelkie dodatkowe biblioteki do zainstalowania w klastrze w celu wykonania zadania.
Definicja działania języka Python w usłudze Databricks
Oto przykładowa definicja JSON działania języka Python usługi Databricks:
{
"activity": {
"name": "MyActivity",
"description": "MyActivity description",
"type": "DatabricksSparkPython",
"linkedServiceName": {
"referenceName": "MyDatabricksLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"pythonFile": "dbfs:/docs/pi.py",
"parameters": [
"10"
],
"libraries": [
{
"pypi": {
"package": "tensorflow"
}
}
]
}
}
}
Właściwości działania języka Python usługi Databricks
W poniższej tabeli opisano właściwości JSON używane w definicji JSON:
| Właściwość | Opis | Wymagane |
|---|---|---|
| name | Nazwa działania w potoku. | Tak |
| description (opis) | Tekst opisujący działanie. | Nie |
| typ | W przypadku działania języka Python usługi Databricks typ działania to DatabricksSparkPython. | Tak |
| linkedServiceName | Nazwa połączonej usługi Databricks, na której działa działanie języka Python. Aby dowiedzieć się więcej o tej połączonej usłudze, zobacz artykuł Compute linked services (Połączone usługi obliczeniowe ). | Tak |
| pythonFile | Identyfikator URI pliku języka Python do wykonania. Obsługiwane są tylko ścieżki systemu plików DBFS. | Tak |
| parameters | Parametry wiersza polecenia, które zostaną przekazane do pliku języka Python. Jest to tablica ciągów. | Nie |
| biblioteki | Lista bibliotek do zainstalowania w klastrze, które zostaną wykonane zadanie. Może to być tablica ciągów <, obiektów> | Nie |
Obsługiwane biblioteki dla działań usługi Databricks
W powyższej definicji działania usługi Databricks określisz następujące typy bibliotek: jar, egg, maven, pypi, cran.
{
"libraries": [
{
"jar": "dbfs:/mnt/libraries/library.jar"
},
{
"egg": "dbfs:/mnt/libraries/library.egg"
},
{
"maven": {
"coordinates": "org.jsoup:jsoup:1.7.2",
"exclusions": [ "slf4j:slf4j" ]
}
},
{
"pypi": {
"package": "simplejson",
"repo": "http://my-pypi-mirror.com"
}
},
{
"cran": {
"package": "ada",
"repo": "https://cran.us.r-project.org"
}
}
]
}
Aby uzyskać więcej informacji, zobacz dokumentację usługi Databricks dla typów bibliotek.
Jak przekazać bibliotekę w usłudze Databricks
Możesz użyć interfejsu użytkownika obszaru roboczego:
Korzystanie z interfejsu użytkownika obszaru roboczego usługi Databricks
Aby uzyskać ścieżkę dbfs biblioteki dodanej przy użyciu interfejsu użytkownika, możesz użyć interfejsu wiersza polecenia usługi Databricks.
Zazwyczaj biblioteki Jar są przechowywane w obszarze dbfs:/FileStore/jars podczas korzystania z interfejsu użytkownika. Listę można wyświetlić za pośrednictwem interfejsu wiersza polecenia: databricks fs ls dbfs:/FileStore/job-jars
Możesz też użyć interfejsu wiersza polecenia usługi Databricks:
Postępuj zgodnie z instrukcjami kopiowania biblioteki przy użyciu interfejsu wiersza polecenia usługi Databricks
Korzystanie z interfejsu wiersza polecenia usługi Databricks (kroki instalacji)
Aby na przykład skopiować plik JAR do plików dbfs:
dbfs cp SparkPi-assembly-0.1.jar dbfs:/docs/sparkpi.jar