Kopiowanie różnicowe z bazy danych z tabelą kontrolek
DOTYCZY: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
W tym artykule opisano szablon, który jest dostępny do przyrostowego ładowania nowych lub zaktualizowanych wierszy z tabeli bazy danych do platformy Azure przy użyciu zewnętrznej tabeli kontroli, która przechowuje wartość o wysokiej wartości limitu.
Ten szablon wymaga, aby schemat źródłowej bazy danych zawierał kolumnę sygnatury czasowej lub klucz przyrostowy w celu zidentyfikowania nowych lub zaktualizowanych wierszy.
Uwaga
Jeśli masz kolumnę sygnatury czasowej w źródłowej bazie danych w celu zidentyfikowania nowych lub zaktualizowanych wierszy, ale nie chcesz tworzyć zewnętrznej tabeli kontroli do użycia na potrzeby kopiowania różnicowego, możesz zamiast tego użyć narzędzia do kopiowania danych usługi Azure Data Factory, aby uzyskać potok. To narzędzie używa czasu zaplanowanego przez wyzwalacz jako zmiennej do odczytywania nowych wierszy ze źródłowej bazy danych.
Informacje o tym szablonie rozwiązania
Ten szablon najpierw pobiera starą wartość limitu i porównuje go z bieżącą wartością limitu. Następnie kopiuje tylko zmiany ze źródłowej bazy danych na podstawie porównania dwóch wartości limitu. Na koniec zapisuje nową wartość wysokiego limitu w zewnętrznej tabeli sterowania na potrzeby ładowania danych różnicowych następnym razem.
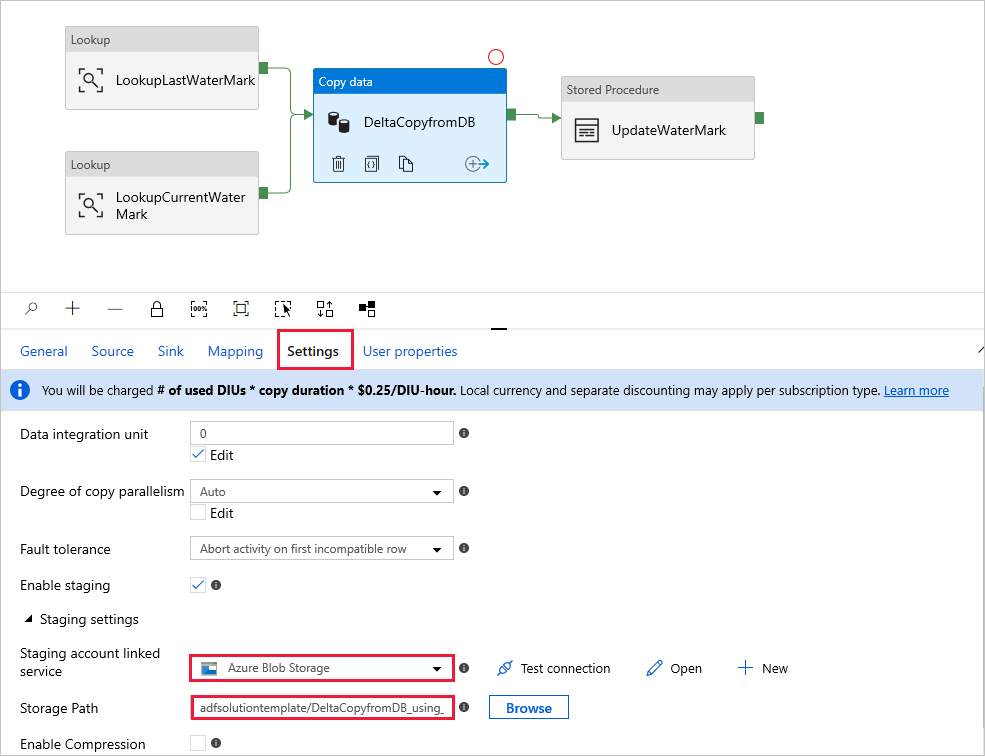
Szablon zawiera cztery działania:
- Odnośnik pobiera starą wartość górnego limitu, która jest przechowywana w zewnętrznej tabeli sterowania.
- Inne działanie Lookup pobiera bieżącą wartość limitu górnego ze źródłowej bazy danych.
- Kopiuje tylko zmiany ze źródłowej bazy danych do magazynu docelowego. Zapytanie identyfikujące zmiany w źródłowej bazie danych jest podobne do "SELECT * FROM Data_Source_Table WHERE TIMESTAMP_Column > "last high-watermark" i TIMESTAMP_Column <= "current high-watermark".
- SqlServerStoredProcedure zapisuje bieżącą wartość limitu górnego limitu w zewnętrznej tabeli sterowania dla kopii różnicowej przy następnym kroku.
Szablon definiuje następujące parametry:
- Data_Source_Table_Name to tabela w źródłowej bazie danych, z której chcesz załadować dane.
- Data_Source_WaterMarkColumn to nazwa kolumny w tabeli źródłowej używanej do identyfikowania nowych lub zaktualizowanych wierszy. Typ tej kolumny to zazwyczaj data/godzina, INT lub podobne.
- Data_Destination_Container jest ścieżką główną miejsca, w którym dane są kopiowane do magazynu docelowego.
- Data_Destination_Directory to ścieżka katalogu znajdująca się w katalogu głównym miejsca, w którym dane są kopiowane do magazynu docelowego.
- Data_Destination_Table_Name to miejsce, w którym dane są kopiowane do magazynu docelowego (w przypadku wybrania opcji "Azure Synapse Analytics" jako miejsca docelowego danych).
- Data_Destination_Folder_Path to miejsce, w którym dane są kopiowane do magazynu docelowego (w przypadku wybrania opcji "System plików" lub "Azure Data Lake Storage Gen1" jako miejsce docelowe danych).
- Control_Table_Table_Name to zewnętrzna tabela sterowania, która przechowuje wartość wysokiego limitu.
- Control_Table_Column_Name to kolumna w tabeli kontroli zewnętrznej, która przechowuje wartość wysokiego limitu.
Jak używać tego szablonu rozwiązania
Zapoznaj się z tabelą źródłową, która ma zostać załadowana, i zdefiniuj kolumnę wysokiego limitu, która może służyć do identyfikowania nowych lub zaktualizowanych wierszy. Typ tej kolumny może być data/godzina, INT lub podobny. Wartość tej kolumny zwiększa się w miarę dodawania nowych wierszy. Z poniższej przykładowej tabeli źródłowej (data_source_table) możemy użyć kolumny LastModifytime jako kolumny limitu górnego.
PersonID Name LastModifytime 1 aaaa 2017-09-01 00:56:00.000 2 bbbb 2017-09-02 05:23:00.000 3 cccc 2017-09-03 02:36:00.000 4 dddd 2017-09-04 03:21:00.000 5 eeee 2017-09-05 08:06:00.000 6 fffffff 2017-09-06 02:23:00.000 7 gggg 2017-09-07 09:01:00.000 8 hhhh 2017-09-08 09:01:00.000 9 iiiiiiiii 2017-09-09 09:01:00.000Utwórz tabelę sterowania w programie SQL Server lub usłudze Azure SQL Database, aby przechowywać wartość wysokiego limitu dla ładowania danych różnicowych. W poniższym przykładzie nazwa tabeli kontrolnej to watermarktable. W tej tabeli watermarkValue to kolumna, w której jest przechowywana wartość limitu górnego limitu, a jej typ to data/godzina.
create table watermarktable ( WatermarkValue datetime, ); INSERT INTO watermarktable VALUES ('1/1/2010 12:00:00 AM')Utwórz procedurę składowaną w tym samym wystąpieniu programu SQL Server lub usługi Azure SQL Database, które zostało użyte do utworzenia tabeli sterowania. Procedura składowana służy do zapisywania nowej wartości górnej limitu w zewnętrznej tabeli sterowania na potrzeby ładowania danych różnicowych przy następnym ładowaniu.
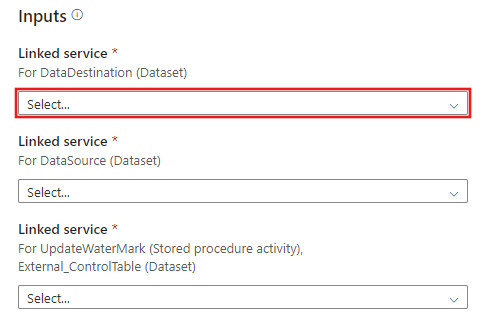
CREATE PROCEDURE update_watermark @LastModifiedtime datetime AS BEGIN UPDATE watermarktable SET [WatermarkValue] = @LastModifiedtime ENDPrzejdź do kopii różnicowej z szablonu Bazy danych . Utwórz nowe połączenie ze źródłową bazą danych, z której chcesz skopiować dane.
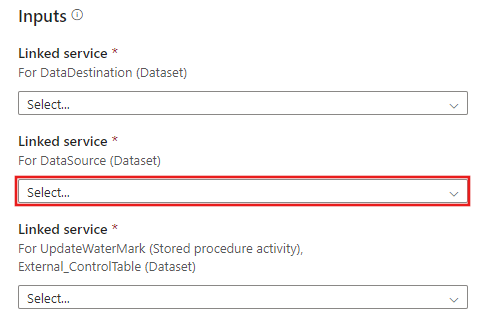
Utwórz nowe połączenie z docelowym magazynem danych, do którego chcesz skopiować dane.
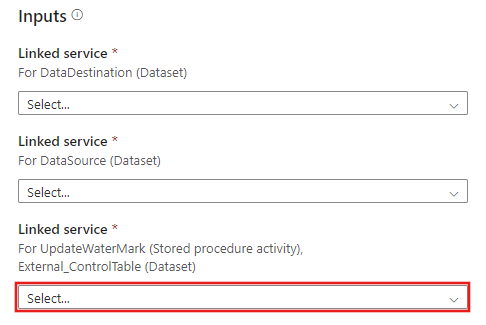
Utwórz nowe połączenie z tabelą kontroli zewnętrznej i procedurą składowaną utworzoną w krokach 2 i 3.
Wybierz Użyj tego szablonu.
Zostanie wyświetlony dostępny potok, jak pokazano w poniższym przykładzie:
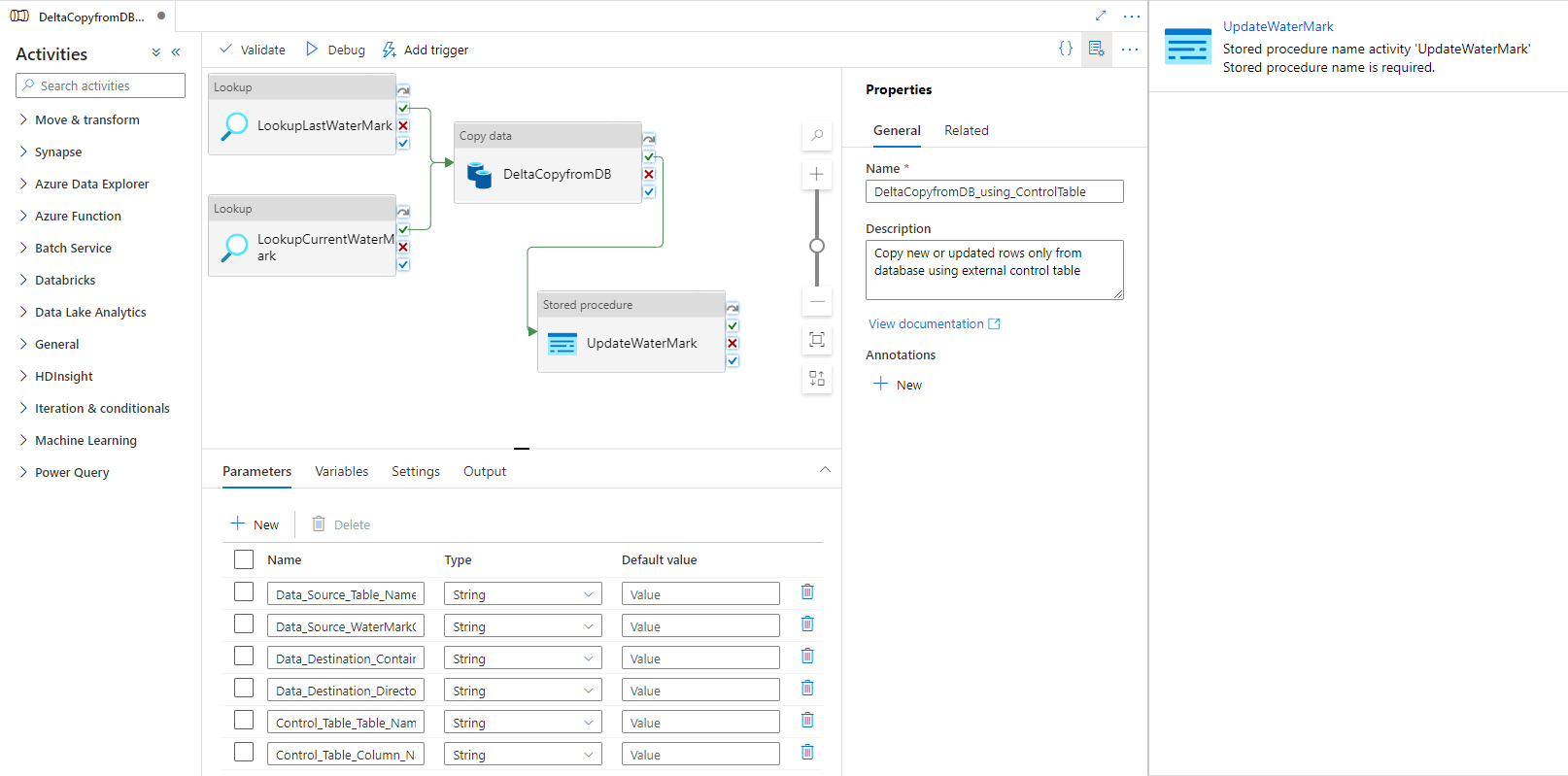
Wybierz pozycję Procedura składowana. W polu Nazwa procedury składowanej wybierz pozycję [dbo].[ update_watermark]. Wybierz pozycję Importuj parametr, a następnie wybierz pozycję Dodaj zawartość dynamiczną.
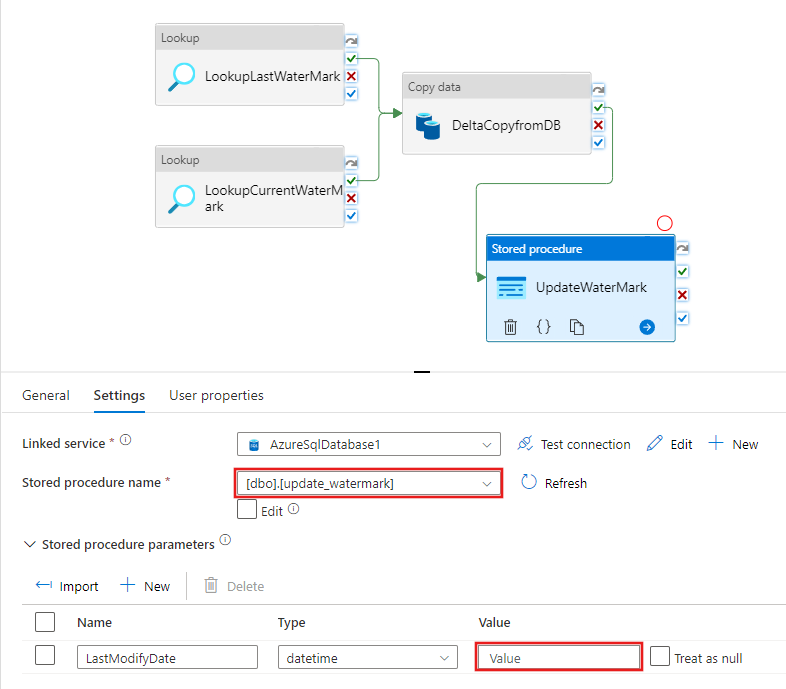
Napisz zawartość @{activity('LookupCurrentWaterMark').output.firstRow.NewWatermarkValue}, a następnie wybierz przycisk Zakończ.
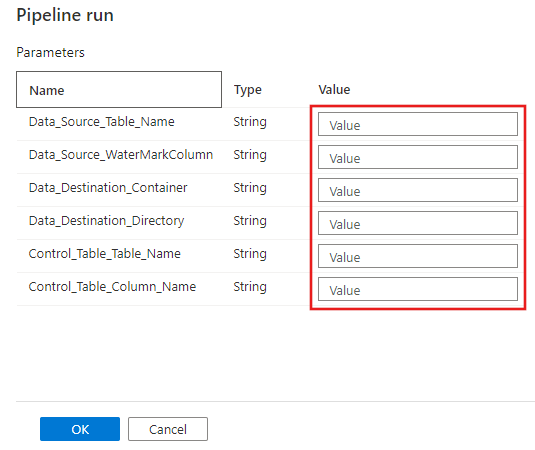
Wybierz pozycję Debuguj, wprowadź parametry, a następnie wybierz pozycję Zakończ.
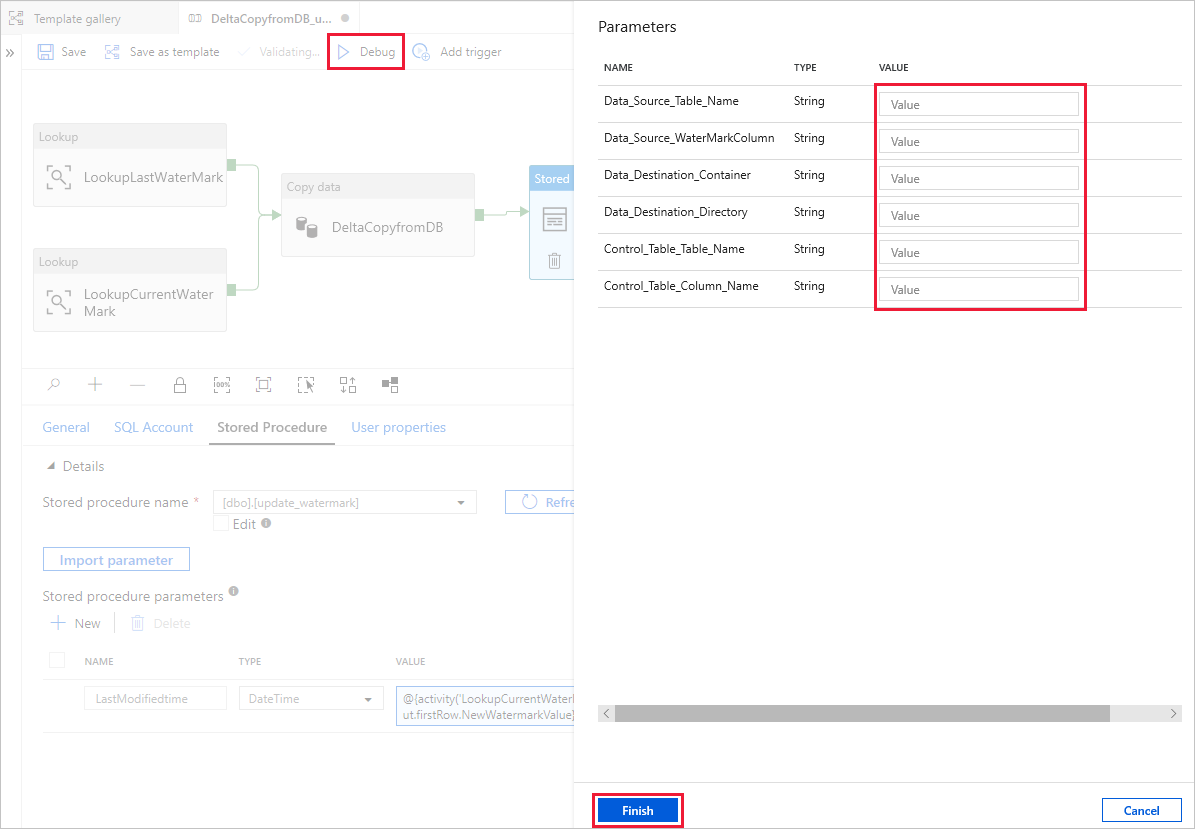
Zostaną wyświetlone wyniki podobne do poniższego przykładu:
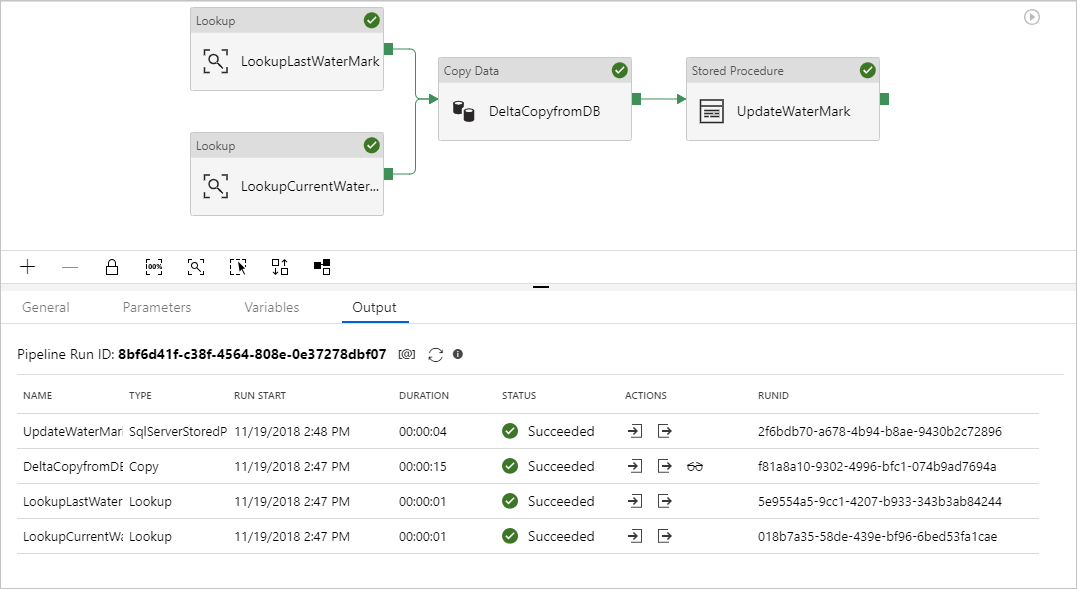
Możesz utworzyć nowe wiersze w tabeli źródłowej. Oto przykładowy język SQL do tworzenia nowych wierszy:
INSERT INTO data_source_table VALUES (10, 'newdata','9/10/2017 2:23:00 AM') INSERT INTO data_source_table VALUES (11, 'newdata','9/11/2017 9:01:00 AM')Aby ponownie uruchomić potok, wybierz pozycję Debuguj, wprowadź parametry, a następnie wybierz pozycję Zakończ.
Zobaczysz, że do miejsca docelowego zostały skopiowane tylko nowe wiersze.
(Opcjonalnie:) Jeśli wybierzesz usługę Azure Synapse Analytics jako miejsce docelowe danych, musisz również podać połączenie z usługą Azure Blob Storage na potrzeby przemieszczania, co jest wymagane przez usługę Azure Synapse Analytics Polybase. Szablon wygeneruje ścieżkę kontenera. Po uruchomieniu potoku sprawdź, czy kontener został utworzony w usłudze Blob Storage.