Przekształcanie źródła w przepływach danych mapowania
DOTYCZY: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
Przepływy danych są dostępne zarówno w usłudze Azure Data Factory, jak i w potokach usługi Azure Synapse. Ten artykuł dotyczy przepływów danych mapowania. Jeśli dopiero zaczynasz transformacje, zapoznaj się z artykułem wprowadzającym Przekształcanie danych przy użyciu przepływu danych mapowania.
Przekształcenie źródła konfiguruje źródło danych dla przepływu danych. Podczas projektowania przepływów danych pierwszy krok polega na skonfigurowaniu transformacji źródłowej. Aby dodać źródło, wybierz pole Dodaj źródło na kanwie przepływu danych.
Każdy przepływ danych wymaga co najmniej jednego przekształcenia źródła, ale można dodać dowolną liczbę źródeł w celu ukończenia przekształceń danych. Możesz połączyć te źródła razem ze sprzężeniami, wyszukiwaniem lub przekształceniem unii.
Każda transformacja źródła jest skojarzona z dokładnie jednym zestawem danych lub połączoną usługą. Zestaw danych definiuje kształt i lokalizację danych, z których chcesz zapisywać dane lub je odczytywać. Jeśli używasz zestawu danych opartego na plikach, możesz użyć symboli wieloznacznych i list plików w źródle, aby pracować z więcej niż jednym plikiem jednocześnie.
Wbudowane zestawy danych
Pierwszą decyzją podjętą podczas tworzenia przekształcenia źródłowego jest to, czy informacje źródłowe są definiowane wewnątrz obiektu zestawu danych, czy w ramach przekształcenia źródłowego. Większość formatów jest dostępna tylko w jednym lub drugim. Aby dowiedzieć się, jak używać określonego łącznika, zobacz odpowiedni dokument łącznika.
Jeśli format jest obsługiwany zarówno w tekście, jak i w obiekcie zestawu danych, istnieją korzyści dla obu tych elementów. Obiekty zestawu danych to jednostki wielokrotnego użytku, które mogą być używane w innych przepływach danych i działaniach, takich jak Kopiowanie. Te jednostki wielokrotnego użytku są szczególnie przydatne w przypadku używania schematu ze wzmocnionymi zabezpieczeniami. Zestawy danych nie są oparte na platformie Spark. Czasami może być konieczne zastąpienie niektórych ustawień lub projekcji schematu w transformacji źródłowej.
Zestawy danych wbudowanych są zalecane w przypadku używania elastycznych schematów, jednorazowych wystąpień źródłowych lub sparametryzowanych źródeł. Jeśli źródło jest silnie sparametryzowane, wbudowane zestawy danych umożliwiają nie tworzenie obiektu "fikcyjnego". Wbudowane zestawy danych są oparte na platformie Spark, a ich właściwości są natywne dla przepływu danych.
Aby użyć wbudowanego zestawu danych, wybierz odpowiedni format w selektorze Typ źródła. Zamiast wybierać źródłowy zestaw danych, należy wybrać połączoną usługę, z którą chcesz nawiązać połączenie.
Opcje schematu
Ponieważ wbudowany zestaw danych jest zdefiniowany wewnątrz przepływu danych, nie istnieje zdefiniowany schemat skojarzony z wbudowanym zestawem danych. Na karcie Projekcja możesz zaimportować schemat danych źródłowych i zapisać ten schemat jako projekcję źródłową. Na tej karcie znajduje się przycisk "Opcje schematu", który umożliwia zdefiniowanie zachowania usługi odnajdywania schematów usługi ADF.
- Użyj przewidywanego schematu: ta opcja jest przydatna w przypadku dużej liczby plików źródłowych skanowanych przez usługę ADF jako źródła. Domyślne zachowanie usługi ADF polega na odnalezieniu schematu każdego pliku źródłowego. Jeśli jednak masz wstępnie zdefiniowaną projekcję już przechowywaną w transformacji źródłowej, możesz ustawić tę wartość na wartość true, a usługa ADF pomija automatyczne odnajdywanie każdego schematu. Po włączeniu tej opcji transformacja źródłowa może odczytywać wszystkie pliki w znacznie szybszy sposób, stosując wstępnie zdefiniowany schemat do każdego pliku.
- Zezwalaj na dryf schematu: włącz dryf schematu, aby przepływ danych zezwalał na nowe kolumny, które nie zostały jeszcze zdefiniowane w schemacie źródłowym.
- Waliduj schemat: ustawienie tej opcji powoduje niepowodzenie przepływu danych, jeśli jakakolwiek kolumna i typ zdefiniowany w projekcji nie są zgodne ze odnalezionym schematem danych źródłowych.
- Wnioskowanie dryfowanych typów kolumn: gdy nowe dryfowane kolumny są identyfikowane przez usługę ADF, te nowe kolumny są rzutowane do odpowiedniego typu danych przy użyciu automatycznego wnioskowania typu usługi ADF.
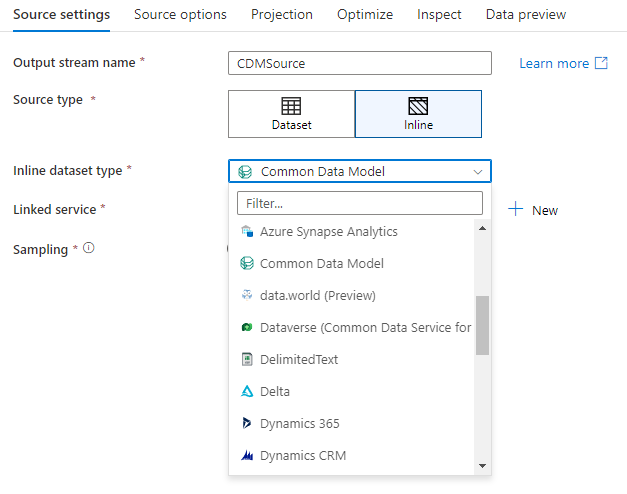
Baza danych obszaru roboczego (tylko obszary robocze usługi Synapse)
W obszarach roboczych usługi Azure Synapse dostępna jest dodatkowa opcja w przekształceniach źródła przepływu danych o nazwie Workspace DB. Dzięki temu można bezpośrednio wybrać bazę danych obszaru roboczego dowolnego dostępnego typu jako dane źródłowe bez konieczności dodatkowych połączonych usług lub zestawów danych. Bazy danych utworzone za pośrednictwem szablonów baz danych usługi Azure Synapse są również dostępne po wybraniu pozycji Baza danych obszaru roboczego.
Obsługiwane typy źródeł
Przepływ danych mapowania jest zgodny z podejściem wyodrębniania, ładowania i przekształcania (ELT) i współpracuje z przejściowymi zestawami danych, które znajdują się na platformie Azure. Obecnie następujące zestawy danych mogą być używane w transformacji źródłowej.
Ustawienia specyficzne dla tych łączników znajdują się na Karta Opcje źródła. Przykłady skryptów przepływu informacji i danych na temat tych ustawień znajdują się w dokumentacji łącznika.
Potoki usługi Azure Data Factory i Synapse mają dostęp do ponad 90 łączników natywnych. Aby uwzględnić dane z tych innych źródeł w przepływie danych, użyj działania kopiowania, aby załadować te dane do jednego z obsługiwanych obszarów przejściowych.
Ustawienia źródła
Po dodaniu źródła skonfiguruj je za pomocą karty Ustawienia źródła. W tym miejscu możesz wybrać lub utworzyć zestaw danych punktów źródłowych. Możesz również wybrać opcje schematu i próbkowania dla danych.
Wartości programowania parametrów zestawu danych można skonfigurować w ustawieniach debugowania. (Tryb debugowania musi być włączony).
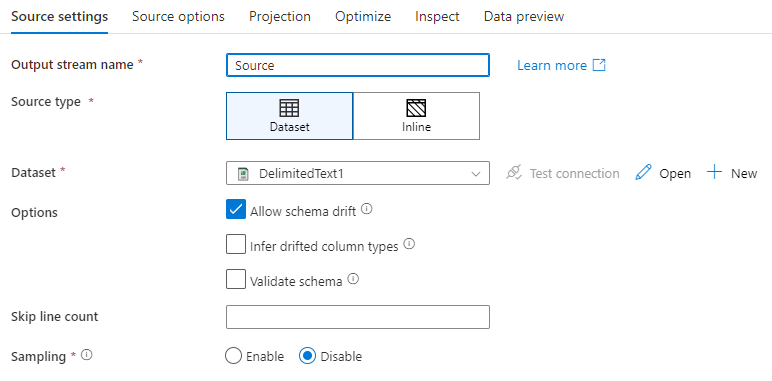
Nazwa strumienia wyjściowego: nazwa przekształcenia źródłowego.
Typ źródła: wybierz, czy chcesz użyć wbudowanego zestawu danych, czy istniejącego obiektu zestawu danych.
Połączenie testowe: sprawdź, czy usługa Spark przepływu danych może pomyślnie nawiązać połączenie z połączoną usługą używaną w źródłowym zestawie danych. Aby włączyć tę funkcję, należy włączyć tryb debugowania.
Dryf schematu: dryf schematu to możliwość natywnego obsługiwania elastycznych schematów w przepływach danych bez konieczności jawnego definiowania zmian kolumn.
Zaznacz pole wyboru Zezwalaj na dryf schematu, jeśli kolumny źródłowe często się zmieniają. To ustawienie umożliwia przepływ wszystkich przychodzących pól źródłowych przez przekształcenia do ujścia.
Wybranie pozycji Wnioskowanie dryfowanych typów kolumn powoduje, że usługa wykrywa i definiuje typy danych dla każdej wykrytej nowej kolumny. Po wyłączeniu tej funkcji wszystkie dryfowane kolumny są ciągiem typu.
Waliduj schemat: jeśli wybrano opcję Weryfikuj schemat , przepływ danych nie może zostać uruchomiony, jeśli przychodzące dane źródłowe nie są zgodne ze zdefiniowanym schematem zestawu danych.
Pomiń liczbę wierszy: pole Pomiń liczbę wierszy określa liczbę wierszy do zignorowania na początku zestawu danych.
Próbkowanie: włącz próbkowanie, aby ograniczyć liczbę wierszy ze źródła. To ustawienie jest używane podczas testowania lub próbkowania danych ze źródła na potrzeby debugowania. Jest to bardzo przydatne podczas wykonywania przepływów danych w trybie debugowania z potoku.
Aby sprawdzić poprawność konfiguracji źródła, włącz tryb debugowania i pobierz podgląd danych. Aby uzyskać więcej informacji, zobacz Tryb debugowania.
Uwaga
Po włączeniu trybu debugowania konfiguracja limitu wierszy w ustawieniach debugowania zastępuje ustawienie próbkowania w źródle podczas podglądu danych.
Opcje źródła
Karta Opcje źródła zawiera ustawienia specyficzne dla wybranego łącznika i formatu. Aby uzyskać więcej informacji i przykładów, zobacz odpowiednią dokumentację łącznika. Obejmuje to szczegóły, takie jak poziom izolacji dla tych źródeł danych, które je obsługują (takie jak lokalne serwery SQL, bazy danych Azure SQL Database i wystąpienia zarządzane usługi Azure SQL) oraz inne ustawienia specyficzne dla źródła danych.
Projekcja
Podobnie jak schematy w zestawach danych, projekcja w źródle definiuje kolumny danych, typy i formaty na podstawie danych źródłowych. W przypadku większości typów zestawów danych, takich jak SQL i Parquet, projekcja w źródle jest stała w celu odzwierciedlenia schematu zdefiniowanego w zestawie danych. Jeśli pliki źródłowe nie są silnie typizowane (na przykład pliki płaskie .csv, a nie pliki Parquet), można zdefiniować typy danych dla każdego pola w transformacji źródłowej.

Jeśli plik tekstowy nie ma zdefiniowanego schematu, wybierz pozycję Wykryj typ danych, aby usługa próbkowała i wnioskowała typy danych. Wybierz pozycję Definiuj format domyślny, aby automatycznie określić domyślne formaty danych.
Resetuj schemat resetuje projekcję do tego, co jest zdefiniowane w przywoływowanym zestawie danych.
Zastąp schemat umożliwia modyfikowanie przewidywanych typów danych w tym miejscu, zastępując typy danych zdefiniowanych schematem. Możesz też zmodyfikować typy danych kolumn w transformacji pochodnej kolumny podrzędnej. Użyj przekształcenia select, aby zmodyfikować nazwy kolumn.
Importowanie schematu
Wybierz przycisk Importuj schemat na karcie Projekcja , aby użyć aktywnego klastra debugowania do utworzenia projekcji schematu. Jest ona dostępna w każdym typie źródłowym. Zaimportowanie schematu w tym miejscu zastępuje projekcję zdefiniowaną w zestawie danych. Obiekt zestawu danych nie zostanie zmieniony.
Importowanie schematu jest przydatne w zestawach danych, takich jak Avro i Azure Cosmos DB, które obsługują złożone struktury danych, które nie wymagają istnienia definicji schematu w zestawie danych. W przypadku wbudowanych zestawów danych importowanie schematu jest jedynym sposobem odwołowania się do metadanych kolumn bez dryfu schematu.
Optymalizowanie transformacji źródłowej
Karta Optymalizacja umożliwia edytowanie informacji o partycji w każdym kroku przekształcania. W większości przypadków użyj bieżącego partycjonowania zoptymalizowanego pod kątem idealnej struktury partycjonowania dla źródła.
Jeśli czytasz ze źródła usługi Azure SQL Database, niestandardowe partycjonowanie źródła prawdopodobnie odczytuje dane najszybciej. Usługa odczytuje duże zapytania przez równoległe nawiązywanie połączeń z bazą danych. To partycjonowanie źródłowe można wykonać w kolumnie lub przy użyciu zapytania.
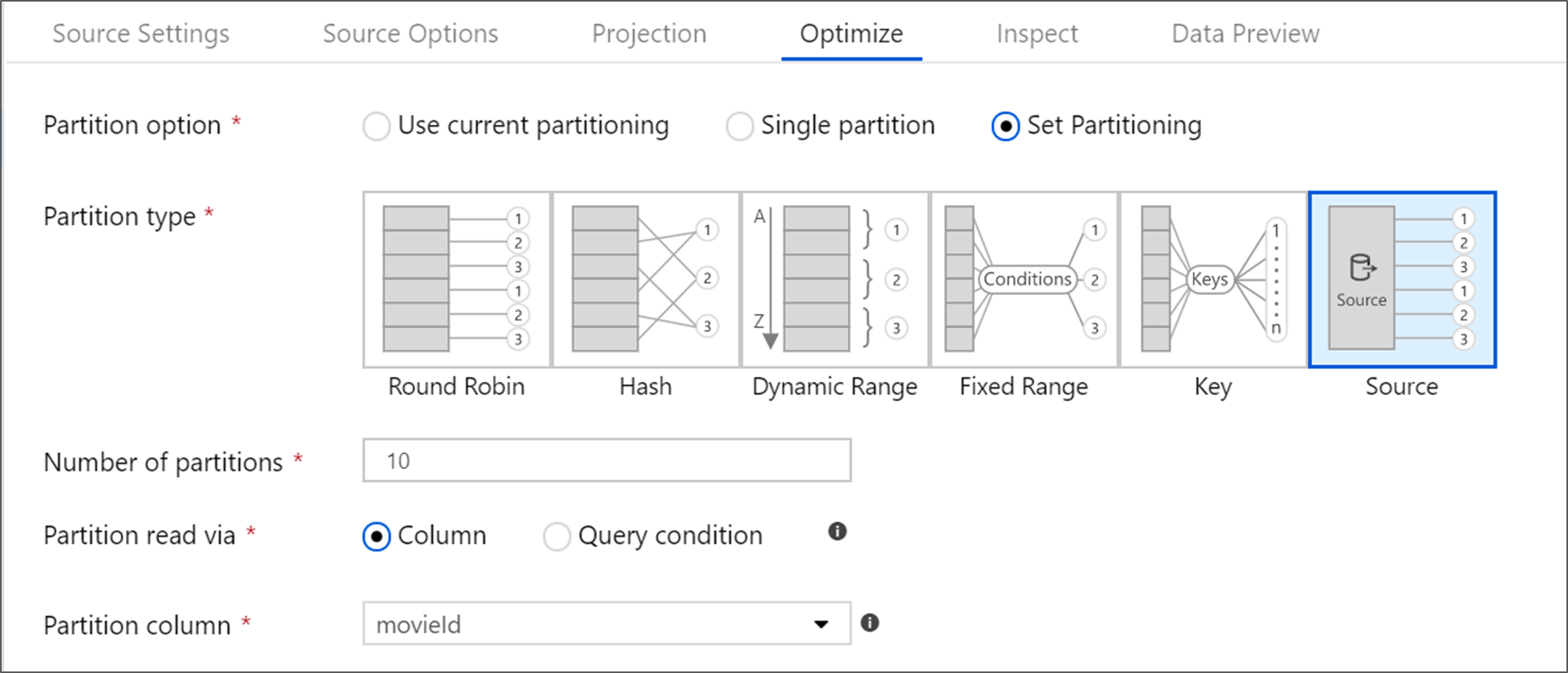
Aby uzyskać więcej informacji na temat optymalizacji w przepływie danych mapowania, zobacz kartę Optymalizowanie.
Powiązana zawartość
Rozpocznij tworzenie przepływu danych przy użyciu przekształcenia kolumny pochodnej i przekształcenia wybierania.