Che cos'è l'osservabilità della rete del servizio Azure Kubernetes? (anteprima)
Kubernetes è uno strumento potente per la gestione delle applicazioni in contenitori. Man mano che gli ambienti in contenitori aumentano di complessità, può essere difficile identificare e risolvere i problemi di rete in un cluster Kubernetes.
L'osservabilità della rete è una parte importante della gestione di un cluster Kubernetes integro ed efficiente. Raccogliendo e analizzando i dati sul traffico di rete, è possibile ottenere informazioni dettagliate sul funzionamento del cluster e identificare potenziali problemi prima di causare interruzioni o riduzione delle prestazioni.
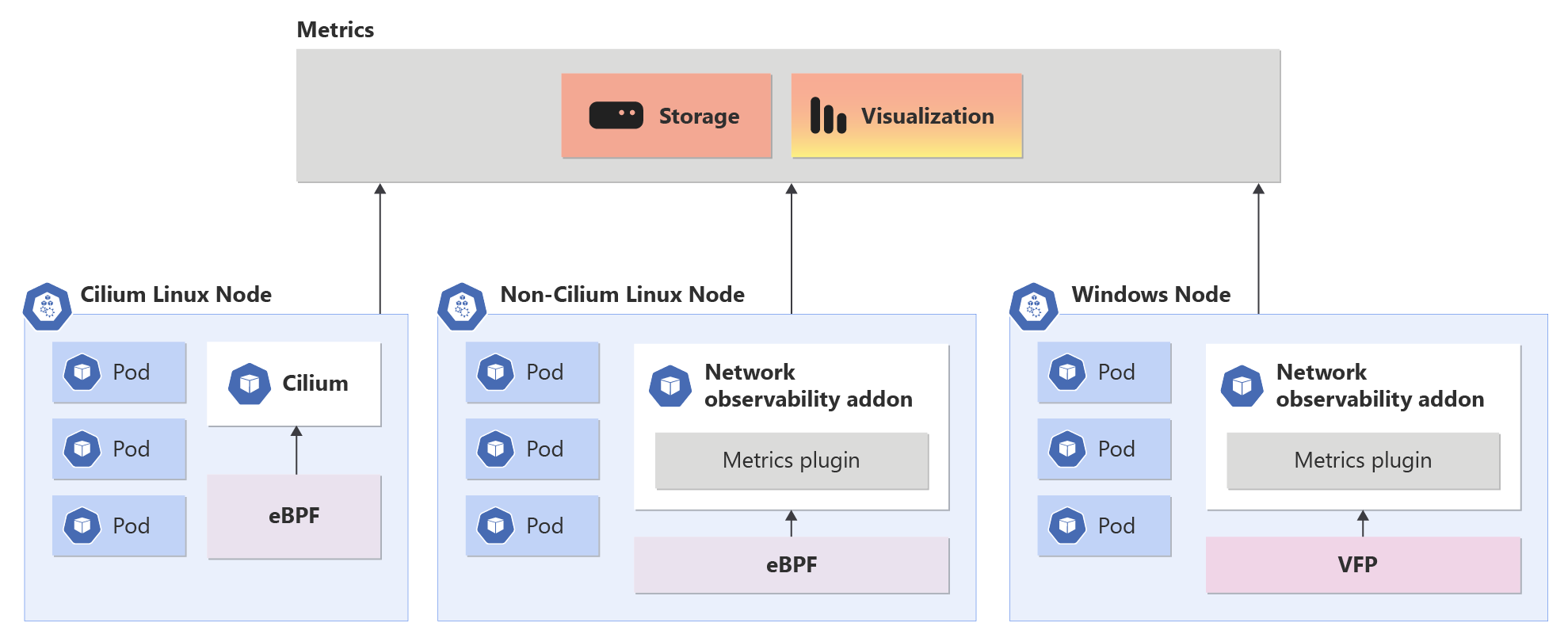
Panoramica del componente aggiuntivo Osservabilità della rete nel servizio Azure Kubernetes
Importante
L'osservabilità della rete del servizio Azure Kubernetes è attualmente disponibile in ANTEPRIMA. Vedere le condizioni per l'utilizzo supplementari per le anteprime di Microsoft Azure per termini legali aggiuntivi che si applicano a funzionalità di Azure in versione beta, in anteprima o in altro modo non ancora disponibili a livello generale.
Il componente aggiuntivo Osservabilità delle rete funziona perfettamente su piani dati Non-Cilium e Cilium. Offre ai clienti funzionalità di livello aziendale per DevOps e SecOps. Questa soluzione offre un modo centralizzato per monitorare i problemi di rete nel cluster per amministratori di rete del cluster, amministratori della sicurezza del cluster e tecnici DevOps.
Quando il componente aggiuntivo Osservabilità della rete è abilitato, consente la raccolta e la conversione di metriche utili in formato Prometheus, che può quindi essere visualizzato in Grafana. In questo contesto sono disponibili due opzioni per l'uso di Prometheus e Grafana: Prometheus e Grafana gestiti di Azure o BYO Prometheus e Grafana.
Prometheus e Grafana gestiti di Azure: questa opzione prevede l'uso di un servizio gestito fornito da Azure. Il servizio gestito si occupa dell'infrastruttura e della manutenzione di Prometheus e Grafana, consentendo di concentrarsi sulla configurazione e la visualizzazione delle metriche. Questa opzione è utile se si preferisce non gestire l'infrastruttura sottostante.
BYO Prometheus e Grafana: in alternativa, è possibile scegliere di configurare le proprie istanze di Prometheus e Grafana. In questo caso, si è responsabili del provisioning e della gestione dell'infrastruttura necessaria per eseguire Prometheus e Grafana. Installare e configurare Prometheus per raschiare le metriche generate dal componente aggiuntivo Network Observability e archiviarle. Analogamente, Grafana deve essere configurato per connettersi a Prometheus e visualizzare i dati raccolti.
Supporto per più CNI: il componente aggiuntivo Osservabilità della rete supporta sia i plug-in di rete Azure CNI che Kubenet.
Metrica
Il componente aggiuntivo Osservabilità di rete supporta attualmente solo le metriche a livello di nodo nelle piattaforme Linux e Windows. La tabella seguente illustra le diverse metriche generate dal componente aggiuntivo Network Observability.
| Nome misurazione | Descrizione | Etichette | Linux | Windows |
|---|---|---|---|---|
| networkobservability_forward_count | Numero totale di pacchetti inoltrati | Direction, NodeName, Cluster | Sì | Sì |
| networkobservability_forward_bytes | Totale conteggio byte inoltrati | Direction, NodeName, Cluster | Sì | Sì |
| networkobservability_drop_count | Totale conteggio pacchetti eliminati | Reason, Direction, NodeName, Cluster | Sì | Sì |
| networkobservability_drop_bytes | Totale conteggio byte eliminati | Reason, Direction, NodeName, Cluster | Sì | Sì |
| networkobservability_tcp_state | Numero di socket attivi TCP in base allo stato TCP. | State, NodeName, Cluster | Sì | Sì |
| networkobservability_tcp_connection_remote | Numero di socket attivi TCP per indirizzo remoto. | Address, Port, NodeName, Cluster | Sì | No |
| networkobservability_tcp_connection_stats | Statistiche sulla connessione TCP. (ad esempio: ACL ritardati, TCPKeepAlive, TCPSackFailures) | Statistiche, NodeName, Cluster | Sì | Sì |
| networkobservability_tcp_flag_counters | Numero di pacchetti TCP per flag. | Flag, NodeName, Cluster | Sì | Sì |
| networkobservability_ip_connection_stats | Statistiche sulla connessione IP. | Statistiche, NodeName, Cluster | Sì | No |
| networkobservability_udp_connection_stats | Statistiche di connessione UDP. | Statistiche, NodeName, Cluster | Sì | No |
| networkobservability_udp_active_sockets | Numero di socket attivi UDP | NodeName, Cluster | Sì | No |
| networkobservability_interface_stats | Statistiche dell'interfaccia. | InterfaceName, Statistic, NodeName, Cluster | Sì | Sì |
Limiti
- Le metriche a livello di pod non sono supportate.
Ridimensiona
Alcune limitazioni di scalabilità si applicano quando si usa Prometheus e Grafana gestiti di Azure. Per altre informazioni, vedere metriche Scrape Prometheus su larga scala in Monitoraggio di Azure
Passaggi successivi
Per altre informazioni sul servizio Azure Kubernetes, vedere Che cos'è il servizio Azure Kubernetes?.
Per creare un cluster del servizio Azure Kubernetes con Network Observability e Prometheus gestito di Azure e Grafana, vedere Configurare l'osservabilità della rete per il servizio Azure Kubernetes gestito da Azure Prometheus e Grafana.
Per creare un cluster del servizio Azure Kubernetes con Network Observability e BYO Prometheus e Grafana, vedere Configurare l'osservabilità della rete per il servizio Azure Kubernetes BYO Prometheus e Grafana.