Announcements, Azure HPC Cache, Compute, Storage
Ankündigung der allgemeinen Verfügbarkeit des neuen Diensts Azure HPC Cache
Posted on
5 min read
Wenn Sie bisher durch die Herausforderungen des Datenzugriffs davon abgehalten wurden, HPC-Aufträge (High Performance Computing) in Azure auszuführen, haben wir gute Neuigkeiten! Mit dem jetzt verfügbaren Dienst Microsoft Azure HPC Cache können Sie anspruchsvollste Workloads in Azure ausführen, ohne Zeit und Kosten in das Umschreiben von Anwendungen investieren zu müssen. Die Daten können Sie an jedem Ort Ihrer Wahr speichern – in Azure oder in Ihrem lokalen Speicher. Durch Minimieren der Latenz zwischen Compute und Speicher ermöglicht der HPC Cache-Dienst nahtlosen Hochgeschwindigkeits-Datenzugriff, den Sie zum Ausführen Ihrer HPC-Anwendungen in Azure benötigen.
Mit Azure die Analysefähigkeiten erweitern – ohne Gedanken an den Datenzugriff
Die meisten HPC-Teams erkennen das Potenzial der Erweiterung ihrer Analysekapazitäten mit Cloudbursting. Obwohl viele Organisationen die Kapazitäts- und Skalierungsvorteile durch das Ausführen von Computeaufträgen in der Cloud für sich nutzen könnten, stellten für viele Benutzer die Größe ihrer Datasets und die Komplexität des Zugriffs auf diese Datasets, die meist in seit langer Zeit bereitgestellten NAS-Ressourcen (Network-Attached Storage) gespeichert sind, ein Hindernis dar. Diese NAS-Umgebungen enthalten häufig Petabytes an Daten, die über lange Zeiträume gesammelt werden und eine große Investition in Infrastruktur darstellen.
Und genau bei diesen Schwierigkeiten kann der HPC Cache-Dienst helfen. Stellen Sie sich den Dienst als einen Edgecache vor, der Zugriff mit niedriger Latenz auf POSIX-Dateidaten an einem oder mehreren Speicherorten bietet, darunter lokaler NAS und in Azure Blob Storage archivierte Daten. Bei HPC Cache können Sie den Analysedurchsatz mithilfe von Azure ganz einfach steigern, selbst bei wachsendem Volumen und Umfang Ihrer relevanten Daten.
Mit zunehmendem Volumen und Umfang der relevanten Daten Schritt halten
Die Geschwindigkeit, mit der in bestimmten Branchen wie Life Sciences neue Daten aufkommen, sorgt für eine stetige Zunahme von Volumen und Umfang der relevanten Daten. Relevante Daten sind in diesem Zusammenhang etwa Datasets, die nach der Erfassung eine Analyse und Interpretation erfordern, die wiederum nachgeschaltete Aktivitäten mit sich bringen. Ein entschlüsseltes Genom kann beispielsweise Hunderte Gigabyte umfassen. Mit steigender Geschwindigkeit und Parallelisierung der Entschlüsselungsaktivitäten wächst auch die Menge an Daten, die gespeichert und interpretiert werden müssen – und Ihre Infrastruktur muss dabei mithalten können. Ihre Leistung beim Sammeln, Verarbeiten und Interpretieren handlungsrelevanter Daten – also Ihre Analysekapazität – hat direkte Auswirkungen auf die Fähigkeit Ihrer Organisation, die Anforderungen der Kunden zu erfüllen und neue Geschäftsoptionen zu nutzen.
Einige Organisationen reagieren auf wachsende Anforderungen an den Analysedurchsatz durch Bereitstellen einer entsprechend größeren lokalen HPC-Umgebung mit einem Hochgeschwindigkeitsnetzwerk und leistungsstarkem Speicher. Für viele Unternehmen stellt das Erweitern der lokalen Umgebung jedoch eine zunehmend schwierigere und kostspieligere Herausforderung dar. Wie können Sie beispielsweise neue Anforderungen an die Kapazität präzise vorhersagen und wirtschaftlicher umsetzen? Wie gleichen Sie den Lebenszyklus Ihrer Hardware optimal mit Nachfragespitzen ab? Wie können Sie sicherstellen, dass der Speicher hinsichtlich Latenz und Durchsatz an den Computeanforderungen ausgerichtet bleibt? Schließlich: Wie bewältigen Sie das alles mit einem begrenzten Budget und begrenzten Mitarbeitern?
Azure-Dienste können dabei helfen, Ihren Analysedurchsatz einfacher und kosteneffektiver über die Kapazität Ihrer bestehenden HPC-Infrastruktur hinaus zu erweitern. Sie können mit Tools wie Azure CycleCloud und Azure Batch Computeaufträge in virtuellen Azure-Computern (VMs) orchestrieren und planen. Verwalten Sie die Kosten und die Skalierung durch Einsetzen von VMs mit geringer Priorität sowie Azure-VM-Skalierungsgruppen noch effektiver. Verwenden Sie die neuesten virtuellen Computer der H- und N-Serie von Azure, um die Leistungsanforderungen Ihrer komplexesten Workloads zu erfüllen.
Wie beginnen Sie also? Es ist ganz unkompliziert. Verbinden Sie Ihr Netzwerk über ExpressRoute mit Azure, legen Sie fest, welche VMs Sie verwenden möchten, und koordinieren Sie Prozesse mit CycleCloud oder Batch – und schon ist Ihre burstfähige HPC-Umgebung einsatzbereit. Sie müssen nur noch Daten übermitteln. Hier müssen wir allerdings etwas genauer werden. Dazu benötigen Sie den HPC Cache-Dienst.
HPC zum Sicherstellen eines schnellen, konsistenten Zugriffs auf Daten
Die meisten Organisationen erkennen die Vorteile der Cloud: Eine burstfähige HPC-Umgebung verleiht Ihnen eventuell eine größere Analysekapazität, ohne neue Kapitalinvestitionen zu erfordern. Außerdem bietet Azure weitere Vorteile, indem Sie Ihre aktuellen Planer und andere Toolsets nutzen können, um eine mit Ihrer lokalen Umgebung konsistente Bereitstellung sicherzustellen.
Das ist allerdings der Haken, wenn es um Daten geht. Für Ihre Bibliotheken, Anwendungen und Speicherorte für Daten ist möglicherweise die gleiche Konsistenz erforderlich. Unter Umständen ist eine lokale Analysepipeline auf POSIX-Pfade angewiesen, die bei der Ausführung in Azure gleich den lokalen Pfaden sein müssen. Eventuell sind Daten zwischen Verzeichnissen verknüpft, und diese Verknüpfungen müssen genauso in der Cloud bereitgestellt werden. Die eigentlichen Daten befinden sich möglicherweise an mehreren Speicherorten und müssen aggregiert werden. Vor allem muss die Latenz des Zugriffs konsistent mit den Möglichkeiten der lokalen HPC-Umgebung sein.
Zum Verständnis der Funktionsweise von HPC Cache für diese Anforderungen können Sie sich den Dienst als Edgecache vorstellen, der Zugriff mit niedriger Latenz auf POSIX-Dateidaten von einem oder mehreren Standorten bietet. Beispielsweise kann eine lokale Umgebung einen großen HPC-Cluster enthalten, der mit einer kommerziellen NAS-Lösung verbunden ist. HPC Cache ermöglicht dieser NAS-Lösung den Zugriff auf Azure Virtual Machines, Container oder Routinen für maschinelles Lernen, die über einen WAN-Link agieren. Der Dienst erreicht dies, indem er Clientanforderungen (einschließlich solcher von virtuellen Computern) zwischenspeichert und sicherstellt, dass nachfolgende Zugriffe auf diese Daten über den Cache erfolgen, anstatt wieder auf die lokale NAS-Umgebung zuzugreifen. Dadurch können Sie Ihre HPC-Aufträge mit ähnlicher Leistung ausführen, wie es in Ihrem eigenen Rechenzentrum möglich wäre. Mit HPC Cache können Sie außerdem einen Namespace erstellen, der Daten in mehreren Exporten aus mehreren Quellen umfasst, aber für Clientcomputer nur eine einzige Verzeichnisstruktur anzeigt.
HPC Cache bietet auch in Azure einen blobgestützten Cache (bei uns als „Blob als POSIX“ bezeichnet), über den die Migration dateibasierter Pipelines ohne Umschreiben von Anwendungen erfolgen kann. Beispielsweise kann ein Genforschungsteam Referenzgenomdaten in die Blobumgebung laden, um die Leistung von Sekundäranalyse-Workflows zu optimieren. Dies hilft dabei, Latenzprobleme bei neuen Aufgaben zu vermeiden, die auf statische Referenzbibliotheken oder Tools angewiesen sind.
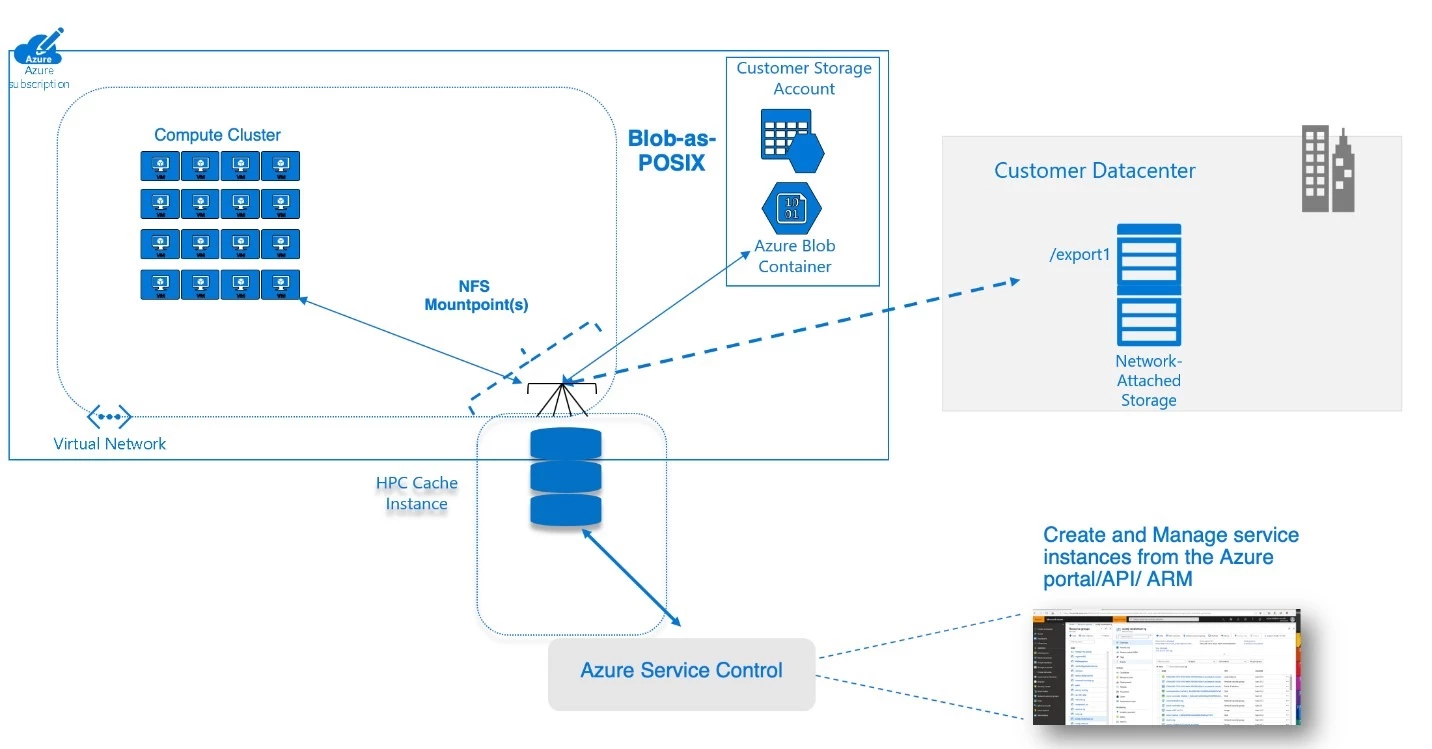
Azure HPC Cache-Architektur
Vorteile von HPC Cache
Zwischenspeicherung des Durchsatzes entsprechend den Workloadanforderungen
HPC Cache bietet drei SKUs: bis zu 2 Gigabyte pro Sekunde (GB/s), bis zu 4 GB/s und bis zu 8 GB/s Durchsatz. Jede dieser SKUs kann Anforderungen von Zehntausenden VMs, Containern u. v. m. verarbeiten. Darüber hinaus können Sie die Größe Ihrer Cachedatenträger so auswählen, dass die Kosten gering bleiben und Sie trotzdem gleichzeitig sicherstellen, dass die erforderliche Kapazität zum Zwischenspeichern verfügbar ist.
Datenbursting aus Ihrem Rechenzentrum
HPC Cache ruft Daten aus Ihrem NAS an jedem beliebigen Ort ab. Führen Sie Ihre HPC-Workload heute aus, und konfigurieren Sie Ihre Datenspeicherungs-Richtlinien über einen längeren Zeitraum.
Konnektivität mit Hochverfügbarkeit
HPC Cache bietet Konnektivität mit Hochverfügbarkeit für Clients. Dies stellt eine zentrale Anforderung für das Ausführen von Computeaufträgen bei größerer Skalierung dar.
Aggregierter Namespace
Die HPC Cache-Funktion für aggregierten Namespace ermöglicht Ihnen, einen Namespace aus verschiedenen Datenquellen aufzubauen. Durch diese Abstraktion der Quellen ist es möglich, mehrere HPC Cache-Umgebungen mit einer konsistenten Datenansicht auszuführen.
Kostengünstigerer Speicher, vollständige POSIX-Konformität mit „Blob als POSIX“
HPC Cache unterstützt blobbasierten, vollständige POSIX-konformen Speicher. HPC Cache behält mithilfe des Formats „Blob als POSIX“ vollständige POSIX-Unterstützung einschließlich fester Links bei. Wenn Sie diese Konformität benötigen, erhalten Sie so vollständiges POSIX zu Blobpreisen.
Beginnen Sie hier
Der Dienst Azure HPC Cache ist bereits verfügbar, und Sie können jetzt gleich darauf zugreifen. Wenden Sie sich für bestmögliche Ergebnisse an Ihr Microsoft-Team oder entsprechende Partner. Diese helfen Ihnen dabei, eine umfassende Architektur aufzubauen, die Ihre spezifischen Geschäftsziele und gewünschten Ergebnisse optimal erfüllt.
Unsere Experten nehmen an der SC19 in Denver (Colorado, USA) teil, der Konferenz zu High Performance Computing, und freuen sich darauf, Ihnen beim Beschleunigen Ihrer dateibasierten Workloads in Azure zu helfen!